Second Issue of the Third Volume of the SISOBserver Journal / Segundo Número del Tercer Volumen de la revista SISOBserver
The SISOB research team has the pleasure to present the sixth issue of SISOBserver. It is part of the dissemination activities of the SISOB project and contains material which reflects our work for the project during the last months. SiSOBserver feeds on the project presence on the social networks. Therefore, we may venture to say that SiSOBserver is not just a journal, but a platform for exchanging ideas and experience between the agents involved in the production and dissemination of Knowledge.
We come back again to offer you a new issue of SiSOBserver. This time, however, is turn to join presentation and farewell. For three years, we have sought to live up to the commitment we entered into with our followers and maintain the identity of the SiSOB project regarding this journal format and the contents offered over the six issues of SiSOBserver.

We have attempted to collect and develop the most innovative contents in connection with the subject as well as others which were of interest to us or our readers. Thus, SiSOBserver has maintained two main sets of issues throughout its three years of life: one linked to the job done for the SiSOB project, and the other which has been the result of various trends with a significant role in the development of the project.
Thus, we have shown the results obtained over the course of the project in combination with those achieved as the result of the interaction between our partners, especially in relation to the study cases and the SiSOB tool. On the other hand, we have been part of and also reported the new trends and research networks, for example, on subjects related to current technology like Open Access, Open Aire, Open Data, Orcid, etc., and also on current issues of the European Commission, governance, calls, etc. They all have a link to the project, its functioning and subject.
Our followers have clearly witnessed the progression of the project over the course of the six issues of the journal. We have attempted to be leaders in our area by having the direct testimony of people and researchers who have told us about their job and given their own view on aspects like scientometrics, research evaluation, etc., or they have just given us an advance on significant issues like the European research programme Horizon 2020.
SiSOBserver was founded as an essential link within the SiSOB communication structure and it has given us the opportunity to reach the three main goals of scientific communication, and hence, of SiSOB: open access, interactivity and information exchange. That is, it has enabled us to publish in open-access format those contents which we have considered should be known by our sphere of influence; it has also enabled us to interact with the scientific community, regardless of whether it was close or not to our sphere of influence, who have shown their interest in the topics addressed. The same has happened with the society, with which we have also interacted. Finally, we have set up a network of contacts and collaboration which may be the beginning of new research experiences and relationships.
The links between SiSOBserver and all the social networks have been constant contributing to complete the circuit we wanted to create. We have kept updated both the journal and SiSOBlog in other specialized and general social networks like Linkedin, Facebook or Twitter allowing us to be loyal to our goal of reaching science to the society and making it part of it.
In the first issue of our journal we said that “We want SiSOBserver to become the tool for knowledge and communication available to everyone. The spirit of this journal is to listen and disseminate information”. We hope not to have failed your expectations and reach that goal. We have attempted to be honest, and we have also learnt too much, especially that science and communication are part of the same spirit: to make a better world and a more understandable environment for everyone.
The farewell of the team of the SiSOB Project is not a matter of good bye but “see you soon”!!

El equipo investigador del Proyecto SISOB tenemos la satisfacción de presentar el sexto número de SISOBserver. Esta revista forma parte de las actividades de diseminación del proyecto SISOB y contiene material que refleja el trabajo realizado en el marco del proyecto durante los últimos meses. Al mismo tiempo, SISObserver se complementa y se retroalimenta de los resultados obtenidos a partir de la presencia de SISOB en las redes sociales, instrumentos que nos sirven para convertirnos en plataforma y foro para intercambiar ideas y experiencias con los agentes involucrados en el proceso de construcción y divulgación del conocimiento científico.
De nuevo les ofrecemos un nuevo número de SISOBserver, aunque en esta ocasión nos toca unir la presentación a la despedida. Durante tres años hemos intentado ser fieles al compromiso que adquirimos con nuestros seguidores, así como mantener la identidad del proyecto SiSOB a través del formato de la revista y de los contenidos que les hemos ofrecido a lo largo de los seis números de SISOBserver.
Hemos tratado de recoger y elaborar los contenidos más innovadores tanto de la temática del proyecto como otros de interés para nosotros y nuestros lectores. De esta forma, SiSOBserver ha mantenido a lo largo de sus tres años de vida dos vertientes temáticas, una vinculada directamente al trabajo que hemos desarrollado en SiSOB, y otra reflejo o resultado de diversas tendencias que han jugado también un importante papel en el desarrollo del proyecto.
Así, hemos presentado los resultados que hemos obtenido a lo largo del proyecto y en la interrelación entre nuestros socios, especialmente de los casos de estudio y de la Herramienta SiSOB. Y, por otro lado, hemos sido eco y parte de nuevas tendencias y redes de investigación, como por ejemplo temas de actualidad tecnológica como Open Access, Open Aire, Open Data, Orcid, y temas de actualidad de la Comisión Europea, gobernanza, convocatorias, etc. y que ha sido también aspectos vinculados al proyecto, su funcionamiento y temática.
Sin duda, nuestros seguidores han sido testigo a lo largo de los seis número de la revista de la progresión técnica del proyecto, al tiempo que hemos tratado de ser líderes en nuestro área al contar con el testimonio directo de personas e investigadores que no sólo nos han hablado de su trabajo, sino que nos han aportado un punto de vista cercano y complementario sobre aspectos como la cienciometría o la evaluación de la investigación, o bien nos han adelantado aspectos tan importantes como el nuevo programa de investigación europeo Horizon 2020.
SiSOBserver nació como un eslabón muy importante de la estructura de comunicación de SiSOB y nos ha brindado la oportunidad de alcanzar los tres objetivos capitales de la comunicación científica y por ende de SiSOB: el acceso abierto, la interactividad y el intercambio de información. Es decir, nos ha permitido publicar en abierto todos los contenidos que consideramos necesario dar a conocer de nuestro proyecto a nuestras áreas de influencia; hemos podido interactuar con la comunidad científica, tanto la cercana a nuestro área de influencia como la que no y que se han visto interesada por los temas que hemos abordado, así como la sociedad en su conjunto; y, finalmente, hemos entrado en una red de contactos y colaboración que pueden ser el inicio de nuevas investigaciones y relaciones.
SiSOBServer se ha mantenido enlazada a todas las redes sociales cerrando así el circuito comunicativo que queríamos crear, manteniendo al día las actualizaciones tanto de la revista, como del blog SiSOBlog, en otras redes sociales especializadas y de carácter generalista, como Linkedin, Facebook, o twitter, manteniéndonos fieles también a nuestro objetivo de acercar la ciencia a la sociedad y hacerla parte de la misma.
En el primer número de la revista decíamos “queremos que SISOBserver sea una herramienta de conocimiento y comunicación al alcance de todos. El espíritu de esta publicación es escuchar y difundir”. Solo esperamos no haberles defraudado y haber alcanzado este objetivo. Nosotros hemos tratado de ser honestos con nuestro trabajo y también hemos aprendido mucho, especialmente que la ciencia y la comunicación son parte de un mismo espíritu, el de hacer un mundo mejor y un entorno más comprensible para las personas.
El equipo del proyecto SiSOB solo quiere despedirse de ustedes con un “hasta pronto”!!
In this section, a new type of diagram is presented, called trajectory diagram. The aim of this metaphor is to enable the analysis of complex scenarios based on temporal relational data in an easy way. Based on Sankey diagrams, trajectory diagrams show the evolution of many entities, as well as their possible interactions in time. It offers a pleasant but powerful interface that enables the analyst to obtain conclusions effortlessly from complex data. This visualisation tool allows also the selection of different magnitudes regarding relational data, providing capabilities to study different points of view for the same phenomenon.
Trajectory diagrams are implemented in the SiSOB workbench, and accepts temporal networks obtained from relational data as input. The result is a plot where time is represented at the bottom of the visualization in ascending order (x-axis). An entity is represented by a rectangle, having a size proportional to the magnitude that is being analysed. For each time unit an enumeration of entities is provided, building parallel columns. Ties exist between entities from left to right, and represent any kind of relation (e.g., there exist common subject categories between consecutive publication items). These ties can also represent the strength of the link for a given magnitude (for example, the number of common subject categories shared by the related items).
Following, the use of this diagram is illustrated in two case studies (detailed in deliverables D7.3 and D8.4 of the SiSOB project, respectively).
Case study 1. Tracking research theme development in the UK
Trajectory graphs help to obtain an overview of the degree of thematic mobility exhibited in a sample of researchers or regions. Thematic trajectories describe the evolution of a scientific domain and can help identify the increase and fragmentation of research domains.
We have conducted a pilot study on thematic mobility, based on a large-scale dataset provided by FR, containing detailed information on engineering academics that were employed at the Engineering departments of 40 major UK universities between 1985 and 2007.In order to measure a change in research topics we will focus on a researcher’s academic output and, in particular, their scientific publications. We will draw on publications from the ISI Science Citation Index Expanded (SCI) and devise measures based on the 244 Subject Categories (SCs) assigned by the SCI. The resulting publication database contains information—among others—on ISI SCs for each of the publications, which is essential for applying the model detailed above. In total the search identified 5751 publishing researchers and 82,538 publications with 105,544 researcher-publication pairs. Although all articles considered in this analysis were published in the faculty of engineering, we can find 183 different ISI SCs associated with them.
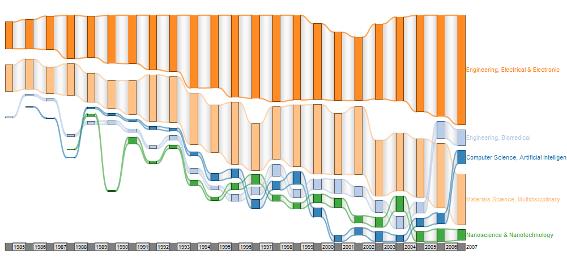
To track research theme development in the UK we look at the development of five major subject categories. We focus exclusively on primary (first) SCs; secondary SCs are ignored in this first exercise. The five fields are Electrical & Electronic Engineering, Multidisciplinary Material Science, Biomedical Engineering, Nanoscience & Nanotechnology and Artificial Intelligence. The trajectory graph is presented in Figure 1. The horizontal axis shows the year of publication. The size of the node represents the number of publications in a field. The vertical axis indicates the relative increase or decrease compared to the previous occurrence of the field.
The graph shows the fluctuation between fields and especially the decrease in Multidisciplinary Materials Science as primary subject area. We further see how certain subject areas have been able to establish themselves as primary research field, for instance Biomedical Engineering and Artificial Intelligence. Overall the descriptive graph seems to suggest that there is an increase in research domains as well as a diversification. While the number of publication increases across all fields, their relative position compared to other fields changes. The graph further seems to support the idea that research domains appear mainly due to new technological developments and specialisation. Though we cannot observe a case of a subject domain disappearing altogether, they can be marginalised or downgraded to a secondary research field.

Figure 1. Trajectory diagram (SISOB Workbench)
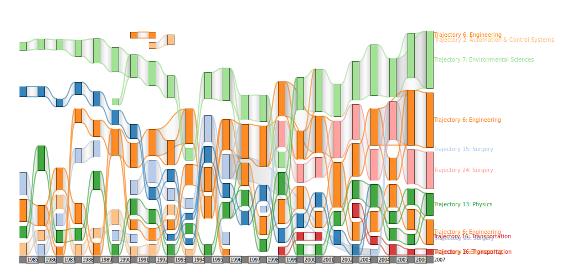
We secondly want to track research theme development using first and secondary research subjects and investigate how SCs diversify or merge over time. Each paper is categorized by one or more SCs. This SC information is used to build a co-occurrence network for each year, and then extract sets of highly correlated terms using Social Network Analysis techniques (e.g., the Louvain method for the detection of communities or themes). Finally, a process of linking is carried out to establish which SCs in consecutive years are correlated, producing trajectories. In Figure 2, the metaphor shows different trajectories for the case of Engineering in the UK for the years 1985 to 2007. The x-axis represents publication years, so for each year (column) a set of themes has been detected (represented by coloured rectangles). The size of each rectangle is proportional to the size of its related SC. For example, in year 1985 the SC Environmental science (light green), Construction and building technologies (blue), Surgery (light blue), Engineering (orange), Physics (green) and, Automation and control systems (light orange) have been detected. From this point on, each category is tracked based on scientific publications.

Figure 2. Thematic trajectories for Engineering in UK from 1985 to 2007
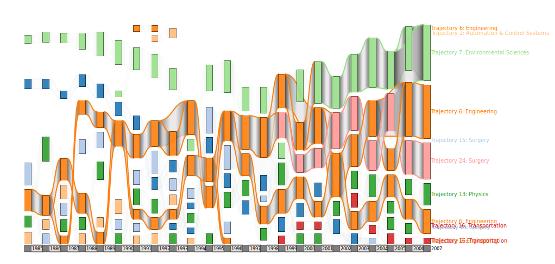
To interpret the diagram we focus on the trajectory of Engineering (orange, Figure 3). This trajectory produces several distinct (non-interdisciplinary) research lines in the earlier years analysed, and from year 1998 onwards these different trajectories produce highly multidisciplinary publications. In fact, the last part of the trajectory is also shared by other trajectories like Environmental sciences, Automation and control Systems, Physics and, Surgery.

Figure 3. Engineering trajectory
Case study 2. Monitoring scientific production in local regions: the case of biotechnology in Andalusia (Spain)
In this case study, we show a simple methodology to monitor research lines in a region during a period of time, based on its scientific production (see D8.4 for details). This research lines are modelled as trajectories in order to be plotted by the SiSOB’s trajectory diagram. As a first step, the highly related topics in which the scientists are researching are detected, producing themes. Then, themes are linked based on common shared topics, producing trajectories. Finally, the trajectories are visualised in an easy-to use yet powerful diagram. This methodology might lead decision-makers to improve their decisions about, for example, where and how much investment should these research lines receive.
These case study take into account those high relevant papers published in journals indexed in the category “Biotechnology and Microbiology” of the Journal of Citation Reports (JCR), Institute of Scientific Information (ISI), from 2004 to 2010 by at least one Andalusian institution. From these data sets (one per year), we follow a process that is better described in three phases: Detection of publication themes, temporal linkage of themes and, visualizing and analysis of trajectories.
In the first phase, a network based on the co-occurrence of keywords in papers is performed for each year. Then, for each network, an algorithm to detect communities is applied. These communities contain sets of high correlated keywords forming themes.
The second phase proceeds with the linkage of themes between networks. This process is based on relating those consecutive communities that fulfil two conditions: the theme has enough elements (i.e., weak communities are discarded) and the count of shared keywords between themes is high enough (i.e., only strong ties are taken into account for linking). This process generates a new network of trajectories containing information about each theme (e.g., number of topics in a theme or its number of papers associated) and tie.
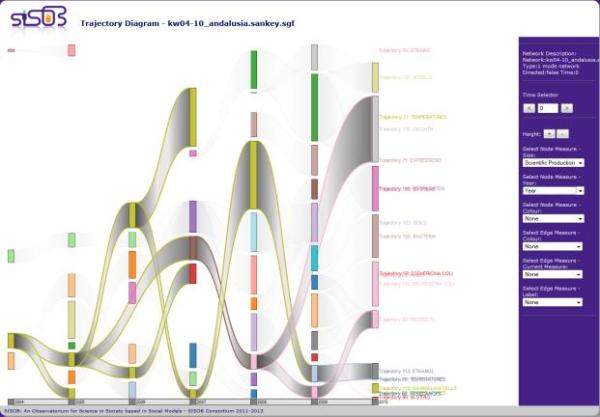
The resulting plot of trajectories for our case study is depicted in Figure 4. As commented before, time is represented in the x-axis while themes detected at each year are represented by rectangles. The length of each rectangle represents the amount of papers related (i.e., the scientific production) with each of them in its corresponding year. The metaphor shows how themes relate through time.

Figure 4. Trajectories detected in Andalusia for the field of Biotechnology (2004-2010).
In a glance, the diagram shows that the scientific production on Biotechnology in Andalusia has been increased in recent years (the sum of the sizes of rectangles per year is bigger recently than in the beginning), as well as the number of trajectories (research lines). This diagram answer this general question, but it also enables us to look at the details of each trajectory.
For example, this metaphor may help to detect current profitable themes. They are those corresponding to larger rectangles at the end of trajectories (year 2010). Some examples are “Growth” (in grey), “Models” (in light yellow), “Degradation” (in pink), “Bacteria” (in light brown) and “Escherichia Coli” (in light pink). The first three themes are contained in long trajectories (since 2004) and thus belong to consolidated research lines, while the last two themes are in very recent trajectories (starting in 2009) that might lead to potentially productive research lines. In the other hand, one might be interested in knowing which trajectories are about to disappear. They are those recently formed (since 2009) that have a decreasing production (“In-vitro” – in red – and “Mammalian-cells” – in yellow).
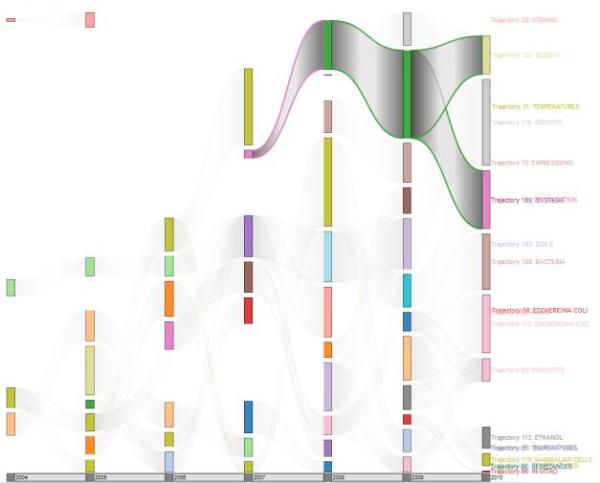
In addition, the components of each individual trajectory can be inspected. In Figure 5 a clear research line has been highlighted. It started in 2007 based on topics about “Degradation” (rectangle in pink at the left), having a scientific production in the region of 7 papers related to the theme. Then, in 2008 the trajectory drifted to terms related to “Fermentation” (green box) and contained 51 papers published. In 2009, the scientific production growth up to 92 papers on the same theme and, finally, in 2010 the trajectory split in two new research lines: one focused in “Models” (in light yellow) and another in “Degradations” (in pink) with 40 and 61 papers published, respectively.

Figure 5. Evolution of a well established trajectory
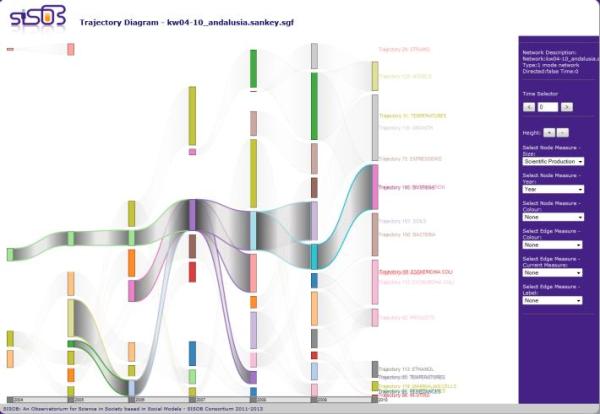
This metaphor also offers the opportunity to answer more complex questions. For example, to know how many research lines has produced a theme, the analyst only have to select the desired theme and see the trajectories highlighted. In Figure 6 (left), we selected “Temperatures” in 2004 and the visualisation tool highlighted a total of five different research lines, allowing us to analyse the effect of this initial theme along time. In the other hand, one may want to know the composition of a theme. This case is depicted in Figure 6 (right), where we selected “Products” in 2010 and the three trajectories that compose this research lines appear highlighted.

Figure 6. Spread (left) and collapsed (right) themes

Finally, and generalizing the latter issues, the metaphor also offers to know the contribution of a theme, that is to study which trajectories have built a theme and how many trajectories produce. Figure 7 shows that in 2007 the theme containing topics related to “Waters” (purple community at the centre) has been formed by three trajectories, and produces another three different research lines in 2008.

Figure 7. Theme contribution in trajectories
Conclusions
As illustrated in the cases of study, representing temporal relational data (e.g., scientific publication data) in trajectory diagrams allow the analysts to extract descriptive results intuitively. In addition, it offers a pleasant but powerful interface that enables the analyst to obtain conclusions effortlessly. Trajectory diagrams are implemented in the SiSOB workbench and accepts temporal networks obtained from relational data as input. The result is a plot where entities are presented, as well as their relations (which produce trajectories).
This metaphor might reach higher implications if used to help decision-makers in their tasks (for example, lead resources by specific trends of scientific productivity in a region; in the latter case of use a possible decision might be to increment the investment in topics related to “Growth”, “Models”, “Escherichia Coli”, “Degradation” and “Bacteria” for the region of Andalusia).
Raúl Fidalgo, University of Málaga Cornelia Meissner, Fondazione Rosselli
Se presenta en este apartado un nuevo tipo de diagrama llamado diagrama de trayectoria. El objetivo de esta metáfora es poder analizar de forma simple escenarios complejos basados en datos relacionales temporales. Basado en los diagramas de Sankey, los diagramas de trayectorias muestran la evolución de varias entidades y sus posibles interacciones en el tiempo. Ofrece una interfaz amigable pero potente que permite al analista obtener conclusiones de datos complejos sin apenas esfuerzo. Esta herramienta de visualización permite además la selección de diferentes magnitudes de acuerdo a los datos relacionales aportando capacidades para el estudio de puntos de vista diferentes para el mismo fenómeno.
Los diagramas de trayectorias se implementan en el workbench de SiSOB aceptando como input redes temporales obtenidas de los datos relacionales. El resultado es una trama donde el tiempo se representa en la parte inferior de la visualización en orden ascendente (eje x). Cada entidad es representada por medio de un rectángulo que tiene un tamaño proporcional a la magnitud que se está analizando. Para cada unidad de tiempo se proporciona una enumeración de entidades construyendo así columnas paralelas. Las entidades pueden estar vinculadas de izquierda a derecha, representando cualquier clase de relación (por ejemplo, existen categorías temáticas comunes entre publicaciones consecutivas). Estos vínculos pueden representar también la fuerza del vínculo para una magnitud dada (por ejemplo, el número de categorías temáticas comunes compartidas por los elementos relacionados).
A continuación, el uso de este diagrama se ilustra en dos estudios de caso (detallados en los resultados del proyecto SiSOBD7.3 y D8.4 respectivamente)
Estudio de caso 1. Seguimiento del tema de la investigación en el Reino Unido
Los gráficos de trayectoria permiten obtener una visión general del grado de movilidadtemática que se presenta en una muestra de investigadores o regiones. Las trayectorias temáticas describen la evolución de un ámbito científico y pueden contribuir a la identificación del aumento y fragmentación de los ámbitos de investigación.
Hemos realizado un estudio piloto sobre la movilidad temática basado en un conjunto de datos a gran escala proporcionados por FR y que contienen información detallada de académicos de ingeniería que estuvieron empleados en departamentos de ingeniería de 40 importantes universidades del Reino Unido entre 1985 y 2007. Para medir el cambio en los temas de investigación nos centramos en la producción académica de un investigador, en concreto en sus publicaciones científicas. Recurrimos a las publicaciones científicas del ISI Science Citation Index Expanded (Índice Expandido de Citación Científica ISI) (SCI) y las medidas ideadas basadas en las 244SubjectCategories (CategoríasTemáticas) (SCs) asignadas por el SCI. La base de datos de publicaciones resultante contiene información -entre otras- de las categorías temáticas de ISI para cada una de laspublicaciones, lo que resulta esencial en la aplicación del modelo detallado anteriormente. En total, la búsqueda identificó 5751 investigadores con publicaciones y 82.538 publicaciones con 105.544 publicaciones conjuntas entre investigadores. Aunque todos los artículos se publicaron en la facultad de ingeniería, podemos hallar 183 categorías temáticas ISI diferentes asociadas a los mismos.
Con el fin de monitorizar el desarrollo de la temática investigadora en el Reino Unido, examinamos el desarrollo de cinco grandes categorías temáticas. Nos centramos exclusivamente en categorías temáticas primarias, ignorando en esta primera parte las secundarias. Las cinco áreas son Ingeniería Eléctrica y Electrónica, Ciencia de Materiales Multidisciplinares, Ingeniería Biomédica, Nanociencia y Nanotecnología e Inteligencia Artificial. En la Gráfica 1 se representan la gráfica de trayectoria. El eje horizontal muestra el año de publicación. El tamaño del nodo representa el número de publicaciones en un área o campo, mientras que el eje vertical indica el relativo aumento o disminucióncomparado con la aparición anterior del campo.
La gráfica muestra la fluctuación entre campos, y especialmente la disminución en Ciencia de Materiales Multidisciplinar como área temática primaria. Más adelante veremos cómo algunas áreas temáticas se han podido establecer por sí mismas como áreas de investigación primarias, como es el caso de la Ingeniería Biomédica e Inteligencia Artificial. Pero sobre todo, lo que la gráfica de descripción parece sugerir es que hay un aumento tanto en los campos de investigación como en la diversificación. Mientras que el número de publicaciones aumenta en todos los campos, su posición relativa cambia si la comparamos con los cambios habidos en otros campos. La gráfica respalda la idea de que los ámbitos de investigación aparecen principalmente debido a la especialización y el desarrollo tecnológico. Aunque no podemos observar el caso de la desaparición total de un área temática, se puede marginar o degradar a un área de investigación secundaria.
Gráfica 1. Diagrama de Trayectoria (Workbench de SiSOB)
En Segundo lugar, queríamos hacer un seguimiento del desarrollo de la temática de investigación usando temas de investigación primarios y secundarios y averiguar cómo se diversifican o surgen las categorías temáticas a lo largo del tiempo. Cada artículose clasificaporuna o más categorías temáticas. Esta información de las categorías temáticas se utiliza para construir una red de coocurrencia por cada año, para después extraer series de términos altamente correlacionados mediante el uso de técnicas de Análisis de Redes Sociales (por ejemplo, el método Louvain para la detección de comunidades o temas). Finalmente se lleva a cabo un proceso de unión para poder establecer qué categorías temáticas se correlacionan en años consecutivos produciendo trayectorias. En la Gráfica 2, la metáfora muestra trayectorias diferentes para el caso de la Ingeniería en el Reino Unido para los años comprendidos entre 1985 y 2007. El eje X representa los años de publicación, y para cada año (columna) se ha detectado un conjunto de temas (representados mediante rectángulos de color). El tamaño de cada rectángulo es proporcional al tamaño de la categoría temática con la que se relaciona. Por ejemplo, en el año 1985, se detectaron las categorías temáticas de ciencia Medioambiental (verde claro), Materiales de Construcción y tecnología de edificios (azul), Cirugía (azul claro), Ingeniería (naranja), Física (verde) y Sistemas de Automatización y control. A partir de este momento, cada categoría se monitoriza mediante las publicaciones científicas.
Gráfica 2. Trayectorias temáticas para la Ingeniería en el Reino Unido desde 1985 a 2007
Para interpretar el diagrama nos centramos en la trayectoria de la Ingeniería (naranja, Gráfica 3). Esta trayectoria produce varias líneas de investigación diferentes (no interdisciplinares) en los primeros años analizados, y desde el año 1998 en adelante, estas trayectorias diferentes producen publicaciones altamente multidisciplinares. De hecho, la última parte de la trayectoria es compartida a su vez por otras como Ciencias Medioambientales, Sistemas de Automatización y control, Física y Cirugía.
Gráfica 3.Trayectoria de Ingeniería
Estudio de Caso 2. Desarrollo de la producción científica en entornos locales: el caso de la biotecnología en Andalucía (España)
En este estudio se muestra una metodología sencilla para observar las líneas de investigación de una región durante un periodo de tiempo basándonos en su producción científica. (Véase D8.4 para más detalle). Estas líneas de investigación se modelan como trayectorias para poderse mostrar en el diagrama de Trayectorias de SiSOB. Como primer paso, se detectan los temas altamente relacionados sobre los que se lleva a cabo una investigación, produciendo temas. A continuación, los temas se unen de acuerdo a los temas comunes que comparten, produciendo así trayectorias. Finalmente, las trayectorias se visualizan en un diagrama potente pero fácil de usar. Esta metodología permite a los responsables de la toma de decisiones mejorar sus decisiones en torno a, por ejemplo, dónde y cuánto invertir en estas líneas de investigación.
Estos casos de estudio tienen en cuenta los artículos de mayor relevancia publicados en revistas indexadas en la categoría de “Biotecnología y Microbiología” del Journal Citation of Reports (JCR) (Revista de Citación de Informes) perteneciente al Institute of Scientific Information (ISI) (Instituto de Información Científica), desde 2004 a 2010 por,al menos, una institución andaluza. A partir de esta serie datos (uno por año), seguimos un proceso que se describe mejor en tres fases: detección de los temas de publicación, conexión temporal de temas y visualización y análisis de trayectorias.
En la primera fase, se realiza por cada año una red basada en la coocurrencia de palabras clave en artículos. A continuación, por cada red, se aplica un algoritmo de detección de comunidades. Dichas comunidades contienen series de palabras clave altamente correlacionadas que forman temas. En la segunda fase se procede a la conexión de los temas entre redes. Este proceso se basa en relacionar a esas comunidades consecutivas que cumplen dos condiciones: el tema contiene suficientes elementos (por ejemplo, se descartan comunidades débiles) y el conteo de palabras clave compartidas por los temas es lo suficientemente alto (por ejemplo, sólo se consideran conexiones fuertes). Este proceso genera una nueva red de trayectorias que contienen información sobre cada tema (por ejemplo, número de tópicos en un tema o número de artículos asociados) y cada unión.
El trazado de trayectorias resultante para nuestro estudio de caso se representa en la Gráfica 4. Como ya se comentó anteriormente, el tiempo se representa en el eje x mientras que los temas detectados en cada año se representan mediante rectángulos. La longitud de cada rectángulo representa el número de artículos relacionados (por ejemplo, la producción científica) con cada uno de ellos en su correspondiente año. La metáfora muestra cómo los temas se relacionan en el tiempo.

Gráfica 4. Trayectorias detectadas en Andalucía en el área de Biotecnología (2004-2010)
A simple vista, el diagrama muestra que la producción científica en Biotecnología en Andalucía ha aumentado en los últimos años (la suma del tamaño de los rectángulos por año es mayor en los últimos años que al principio), así como el número de trayectorias (líneas de investigación). El diagrama responde a esta cuestión de orden general, pero permite también examinar con detalle cada trayectoria.
Por ejemplo, esta metáfora puede contribuir a la detección de temas de actualidad beneficiosos, que son los que corresponden a los rectángulos más amplios al final de las trayectorias (año 2010). Entre otros están el “Crecimiento” (“Growth”)(en verde), “Modelos” (“Models”)(en amarillo claro), “Degradación” (“Degradation”)(en rosa), “Bacterias” (“Bacteria”) (en marrón claro) y “EscherichiaColi” (en rosa claro). Los primeros tres temas aparecen en las trayectorias largas (desde 2004) y además pertenecen a líneas de investigación consolidadas, mientras que los dos últimos temas se encuentran en trayectorias bastante más recientes (comenzaron en 2009) que podrían convertirse en líneas de investigación productivas. Por otra parte, cualquiera puede interesarse por saber que trayectorias están a punto de desaparecer, que son aquellas que se han formado recientemente (desde 2009) y con una producción decreciente (“in vitro” -en rojo- y “células mamarias”-en amarillo-).
Además, se pueden inspeccionar los componentes de cada trayectoria. En la Gráfica 5 se destaca una clara línea de investigación. Comenzó en 2007 basándose en temas sobre la “degradación” (rectángulo rosa a la izquierda) con una producción científica de 7 artículos en la región. Después, en 2008 la trayectoria se desvió a términos relacionados con la “Fermentación” (caja verde), y contenía 51 artículos publicados. En el año 2009 la producción científica aumentó hasta los 92 artículos del mismo tema y, finalmente, en el año 2010 la trayectoria se dividió en dos nuevas líneas de investigación: una centrada en “Modelos” (amarillo claro) y otra en “Degradaciones” (rosa) con 40 y 61 artículos publicados respectivamente.
Gráfica 5. Evolución de una trayectoria bien establecida
Esta metáfora ofrece también la oportunidad de responder a preguntas más complejas, por ejemplo, saber cuántas líneas de investigación ha producido un tema. Para ello, el analista sólo tiene que seleccionar el tema deseado y ver las trayectorias destacadas. En la Gráfica 6 (izquierda), seleccionamos “Temperaturas” en 2004 y la herramienta de visualización destacaba un total de 5 líneas diferentes de investigación, lo que nos permite analizar el efecto de este tema inicial a lo largo del tiempo. Por otra parte, cualquiera puede tener interés por saber la composición de un tema, lo cual se representa en la Gráfica 6 (derecha), donde seleccionamos “Productos” en 2010 y aparecen destacadas las tres trayectorias que componen esta línea de investigación.
Gráfica 6. Temas extendidos (izquierda) y colapsados (derecha)
Finalmente y para generalizar en torno a estos últimos aspectos, la metáfora permite saber la contribución de un tema, es decir, estudiar qué trayectorias han construido un tema y cómo se extienden muchas de ellas. La Gráfica 7 muestra que en 2007 el tema que contenía tópicos relacionados con “Aguas” (comunidad violeta en el centro) se ha formado por tres trayectorias, y produce otras tres líneas de investigación en 2008.
Gráfica 7. Contribución de los temas a las trayectorias
Conclusiones
Como se ha ilustrado en los estudios de caso, la representación temporal de datos relacionales (por ejemplo, datos de publicaciones científicas) en los diagramas de trayectoria permiten a los analistas extraer resultados descriptivos instintivamente además de ofrecer una interfaz amigable pero potente al mismo tiempo que permite obtener conclusiones sin apenas esfuerzo. Los diagramas de trayectorias se aplican al Workbench de SiSOB permitiendo a éste aceptar redes temporales obtenidas a partir de datos relacionales como input. El resultado es un entramado en el que se presentan las entidades y sus relaciones (que producen a su vez trayectorias)
Esta metáfora podría tener mayores repercusiones si los responsables de lastomas de decisión las utilizaran para llevar a cabo sus tareas (por ejemplo conducir los recursos según las tendencias en la productividad científica de una región; en el último caso de uso una posible decisión podría aumentar la inversión en temas relativos al “Crecimiento”, “Modelos”, “Escherichia Coli”, “Degradación” y “Bacterias” para la región de Andalucía.
Raúl Fidalgo, University of Málaga Cornelia Meissner, Fondazione Rosselli
Knowledge trajectories and role patterns / Trayectorias de Conocimiento y patrones funcionales
What are trajectories and when may they be helpful?
Trajectories offer a multidimensional taxonomy emphasizing the temporal aspect of knowledge sharing. Introducing trajectories in the SISOB workbench enriches analysis possibilities for the knowledge sharing case. As a transient format trajectories hold information on actors, in this case researchers and institutions, as well as artifacts, here publications and their attributes. Attributes like geographic position or different types of actors, as suggested for career trajectories, help identifying knowledge spillovers, if they are followed over a period of time. Following attributes exploits the tacit nature of knowledge to find knowledge trails. Searching, sorting and selecting are basic tasks on trajectories. Trajectories can subsequently be converted into a number of 2-mode-networks for further analysis.
Trajectories are lists of entries (figure 31). Entries hold information about a researcher connected to an institution in one year. Researchers are identified by a number, their initials and name. Research topics and a list of papers authored in the given year complete an entry.

Figure 31. Since initials and names are not necessarily unique, researchers are identified by ID. Entries exist per researcher, institution and year.

Figure 32. Keywords are extracted from abstracts of papers.
A paper has a title, an abstract, a list of authors and of keywords. Keywords have been extracted from the abstracts with the help of the KEA (Keyphrase Extraction Algorithm) (figure 32). Topics are an accumulation of all keywords.
Missing years or institutions are roughly estimated, if possible. Missing dates are chosen from the time span of entries before and after the given entry, assuming a chronological order. Institutions are extracted from publications or it is assumed, that they did not change. Entire missing entries are filled with CV information of the preceding year. Even with these corrections, empty fields in the trajectory cannot be avoided, where there is no information to base estimation on.
Converting trajectories to networks
It is possible to convert trajectories to 2-mode-networks in the Pajek .net format via the TrajectoryToNet converter in the SISOB workbench for further analysis. The following networks can be generated:
- Author-Institution network
- Author-Publication network
- Institution-Publication network
- Author-Topic network
- Topic-Publication network
- Topic-Institution network
By folding these graphs, it is possible to gain e.g. co-authorship networks on the fly.
Following knowledge is often accomplished by following the mechanisms that help spreading the knowledge. Abramo, D’Angelo and Solazzi (2011) for example looked at co-authored papers to detect knowledge spill-overs. This addition to the SISOB workbench follows the knowledge itself, concentrating on where and when it appears, leaving how it got there to further research. This can be an advantage, since it also detects knowledge transfer by less measureable routes. The actors in this scenario are R&D institutions, which give the knowledge produced within their walls a position. The knowledge is represented by topics, which are keywords extracted from abstracts of papers. Institutions publishing on these topics are mapped onto a Google map similarly to the approach taken by Bornmann, Leydesdorff, Walch-Solimenta and Ettl (2011), who showed, that highly cited papers are often centred around big cities. The GoogleMapAgent shows rise, geographic distribution and movement of a single selected topic over time on a Google map. Time slices are years. Thus, it is possible to study the lifecycle of a topic: Where it appears, how fast and where it spreads, if it tends to stick to institutions or oscillates between them and how fast and where it descends.
One goal of the tool is to examine, where topics appear for the first time. A topic does not necessarily have to have only one starting point. Either it could have spread even within the first time slice or different institutions could produce the same knowledge simultaneously. In times of globalization, public databases, Google scholar and social media, artefacts like papers are available all around the world within seconds. But knowledge can be of tacit nature and strongly bound to an actor. It would be interesting to see, if under these circumstances the statement of Glaeser, Kallal, Scheinkman and Schleifer (1992) still holds true, that “intellectual breakthroughs cross hallways and streets more easily than oceans and continents”. Eventually this agent can be used to detect typical lifecycles of topics, which could lead to the development of lifecycle patterns.
Working with an example in the SISOB workbench
The collection with geodata, which the TrajectoryBuilderSimulator provides for this workflow, is a purely imaginary collection in the format trajectory. It is compiled only for the purpose of exploring the possibilities the GoogleMapAgent provides. Therefore analysis does not lead to any valid results.
The collection consists of eighteen entries that span the four years from 2009 to 2012. It includes nine institutions located on four continents, with three of them situated in Boston, two of them situated in the south of Great Britain in order to cover distances from a few hundred meters to a few thousand kilometers. Institutions are the University of Duisburg-Essen, Harvard University, Massachusetts Institute of Technology, University of Sydney, University of Oxford, University of Cambridge, University of Zagreb, Boston University and University of Moscow. Geographic coordinates for these institutions are made available by the tool. There are eight topics to choose from (Nanotechnology, Biomolecular Engineering., Bioinformatics, Material Sciences, Neurosciences, Computergrafics, Electronic Business and Social Network Analysis). “Nanotechnology” is listed for every entry and will therefore return the full trajectory and give the most comprehensive demonstration.
Workflow
Figure 33 shows the workflow in the SISOB workbench. The GoogleMapAgent takes a trajectory provided by the TrajectoryBuilderSimulator as input. The TrajectoryFilterTime, which can be applied optionally, reduces the trajectory to entries between the years 2009 and 2012. Since the GoogleMapAgent is designed to focus on a single research topic, it is imperative for this workflow to use the TrajectoryFilterTopic to determine the topic of interest, which is “nanotechnology” for this example. The GoogleMapAgent finally transfers the information from the trajectory into the Keyhole Markup Language (kml), a XML based notation for geographic information with context or metadata, which is accepted as input by the GoogleMap-API. The result is a link to a Google map, which shows an institution-institution network for the chosen topic for every year within the selected timeframe.

Figure 33. Workflow in the SISOB workbench to depict single topic development on GoogleMap
As can be seen in figure 34, years are distinguished by the colour of their links. Naturally, institution networks for one year form a clique. These networks are folded topic-institution networks, which include only one topic after filtering. Folding away the single topic leaves a clique of institutions. Links stand for the fact, that one or more researchers at the source institution work on the same topic as one or more researchers at the target institution, but do not imply cooperation between institutions. Earlier links in terms of years hide later links. Years and institutions are listed in the menu on the left and can be selected or deselected via checkbox (see figure 35). In the years 2010 and 2012 the number of institutions involved has remained fairly constant, but institutions have changed and the topic has spread widely geographically.

Figure 34. Overviews give a rough estimation on growth and distribution of the network.

Figure 35. A close up reveals three universities in Boston to be part of the network.
A close up on the American continent (figure 35) allows for a more detailed analysis of the institutions involved in this area. Three universities in Boston are part of the network. A click on the node in the map gives the name of the institution, a click on a link indicates source and target. For example, the Massachusetts Institute of Technology has participated in research in the topic during 2009 and 2012.
Actors often fulfill a role within a given context. In the context of knowledge sharing and researcher mobility, roles which are crucial for spreading knowledge or indicate change are of interest. A role therefore is a behavior in the process of acquiring, creating and sharing knowledge. The RolePatternFilter is a new addition to the SISOB workbench designed to identify researchers, who occupy predefined roles. Since their search is automated, they can significantly shorten the process of finding interesting actors and serve as a starting point of research rather than its final result (Klamma et al. 2006).
The patterns newcomer, terminator and continuant (figure 36) have already served as such starting points (Braun et al. 2001, Wagner & Leydesdorff 2005). Braun et al. (2001) applied these patterns to neurosciences and found that newcomers and terminators attach themselves primarily to continuants when co-authoring a paper. Continuants mediate relationships between newcomers and terminators.
In deliverable D8.2 the significance of the knowledge broker role in multidisciplinary networks was mentioned. The RolePatternFilter extends the idea of roles from classical network analysis to roles, which can be derived from trajectories, especially since trajectories stress the development over time. Roles can serve as attributes to an actor.
Implemented Roles
For the SISOB workbench the patterns newcomer, terminator and continuant examined by Braun et al (2001) (originally suggested by Desolla Price & Gürsey 1976) were implemented. These patterns observe publishing behaviour and are defined within a three years timeframe. A newcomer does not publish in the first, but in the following two years. A terminator publishes in the first two, but not in the last year. A continuant publishes in all three years. Matches are newcomers, terminators or continuants in the second year of the timeframe. We extended the continuant pattern to cover the years between first appearance and termination of work (if within the filtered timeframe). Even if there are publishing free years in between, the researcher is still considered a continuant. However, if there were publishing free years, the researcher would be a match for the other two patterns, too. We chose to expand the timeframe, because tests with the CENIDE data on the TrajectoryBuilder showed that either due to missing data or research schedules, there were researchers not having published any papers within a year. To fill that gap, it can be safely assumed, that the researchers continued working on the same topic, if it was identical in the year before and after the missing year (Braun et al. 2001). The same conclusion however cannot be drawn for newcomers and terminators, since that would mean having to extrapolate forwards or backwards from the timeframe given by the input trajectory.

Figure 36. Patterns newcomer, terminator and continuant as implemented in the workbench. Grey boxes indicate the analysed timeframe, red boxes the years, in which the pattern applies.
Additionally suggested roles
The roles trendsetter, diversifier and roamer have been defined in addition to the existing patterns.
A Trendsetter is a newcomer to a new topic. He or she publishes on the topic within the first year of its appearance.
Diversifiers are researchers, who work on an extraordinarily large number of topics simultaneously. They hold a very broad based know-how and might act as mediators. The number of topics appropriate to identify a diversifier might depend on the input data. To adapt to the input data, every researcher, who publishes on more topics than the mean plus the standard deviation calculated from a random year of the dataset is considered a diversifier.
Roamers are scientists, who change institutes quickly. Roamers have high geographic mobility. The pattern is applied to a three years time window: Within that time window, every researcher that works at at least three different institutions is considered a roamer.
Working with an example in the SISOB workbench
The RolePatternFilter works on trajectories because they hold many attributes associated with the researcher plus those associated with papers as described in Deliverable D2.2.
The collection covering 18 researchers and 6 years, which is provided by the TrajectoryBuilderSimulator, is again a purely imaginary trajectory, designed to present the patterns newcomer, terminator and continuant. Therefore, analysis does not lead to any valid results. The trajectory spans the years from 2007 to 2012. The topic “genetics”, one of five topics, returns the full trajectory. The researcher Maria Gardener demonstrates the extended continuant pattern. She has published in the years 2007, 2008, 2011 and 2012. She is matching the continuant pattern from 2008 to 2011, but at the same time is detected as a newcomer in 2011 and as a terminator in 2008.
Workflow
Figure 37 shows the workflow to detect matches for role pattern within the SISOB workbench. The TrajectoryBuilderSimulator provides the trajectory, the filters are optional. Of course it is possible to look for new and retiring researchers on an unfiltered trajectory. In the context of knowledge sharing it is much more interesting to filter the input trajectory by topic as for example, a newcomer to topic “A” is probably at the same time a terminator to topic “B”. If this holds true for a significantly large number of researchers within a short time span, it indicates a shift of interest in the researcher community. The RolePatternFilter is set to find matches for the continuant pattern. Matches are downloaded via ResultDownloader.

Figure 37. Finding role patterns on trajectories in the SISOB workbench.
Matches are listed in a txt-file in the form initials, name, matching years. The file also contains name and description of the chosen pattern.

Figure 38. Matches for the pattern continuant from the test trajectory.
Future steps
The patterns Trendsetter, Diversifier and Roamer are going to be implemented for the RolePatternFilter. For Trendsetters the input trajectory should not be filtered for topics because otherwise the matching algorithm will never be able to detect the beginning of a new topic.
Roles can be considered as attributes to the researchers who matched the pattern. To use this attribute in the following analysis, it would have to be reintegrated into the original data. This leaves two possibilities: First, the matches serve as filtering instructions for the original trajectory. Second, the original trajectory is transformed into SISOB graph format by means of the TrajectoryToNet converter. The researcher nodes are then assigned a role as a property. Both possibilities require the implementation of another agent for the SISOB workbench.
References
Abramo, G., D’Angelo, C. A., Solazzi, M., 2011. A bibliometric tool to assess the regional dimension of university-industry research collaborations, in: Scientometrics, published online 20. December 2011, DOI: 10.1007/s11192-011-0577-5
Bornmann, L., Leydesdorff, L., Walch-Solimena, C., Ettl, C., 2011 Mapping excellence in the geography of science. An apporach made possible by using Scopus data.
Braun, T., Glanzel, W., Schubert, A., 2001. Publication and Cooperation Patterns of the Authors of Neuroscience Journals. Scientometrics, 51, 499-510.
Desolla Price, D., Gürsey, S., 1976. Studies in scientometrics. Part 1. Transience and continuance in scientific authorship. Internation Forum on Information and Documentation. 1, 17–24.
Glaeser, E., Kallal, H., Scheinkman, J., Shleifer, A., 1992: Growth of the cities. J. Polit Econ, 100, 1126-1152.
Klamma, R., Spaniol, M., Denev, D.,2006. PALADIN: A Pattern Based Approach to Know-ledge Discovery in Digital Social Networks. Proceedings of I-KNOW ’06 Graz, Austria, September 6 – 8
Wagner, C. S., and Leydesdorff, L., 2005. Network Structure, Self-Organization and the Growth of International Collaboration in Science. Research Policy, 34, 1608-1618.
¿Qué son las trayectorias y cuando pueden resultar útiles?
Las trayectorias ofrecen una taxonomía multidimensional que enfatiza el aspecto temporal del intercambio de conocimiento. El uso de dichas trayectorias en el workbench de SISOB aumenta las posibilidades de análisis en el citado intercambio. Al tener un formato de carácter temporal, las trayectorias albergan información sobre actores, que en este caso son investigadores e instituciones, además de artefactos, publicaciones y sus características, como la localización geográfica o los tipos de actores, que, según la trayectoria profesional, ayudan a detectar la difusión del conocimiento tras su seguimiento durante un periodo de tiempo. Estos atributos explotan la naturaleza tácita del conocimiento para encontrar su rastro. La búsqueda, clasificación y selección son tareas básicas en las trayectorias y por consiguiente, pueden convertirse en redes bipartitas para su posterior análisis.
Las trayectorias son listas de entradas (ilustración 31) que albergan la información producida durante un año acerca de un investigador ligado a una institución. Los investigadores se identifican por un número, sus iniciales y nombre. La entrada se completa con los temas de investigación y una lista de los artículos redactados durante ese año.

Ilustración 31. Puesto que iniciales y nombres no son únicos, los investigadores se distinguen por su tarjeta de identificación. Las entradas son por investigador, institución y año.
Un artículo tiene título, un resumen contiene una lista de autores y palabras clave. Esta palabras se han extraído de los resúmenes con la ayuda del KEA (Keyphrase Extraction Algorithm, en español Algoritmo de Extracción de Frases Clave) (ilustración 32) Los temas son un cúmulo de palabras clave.
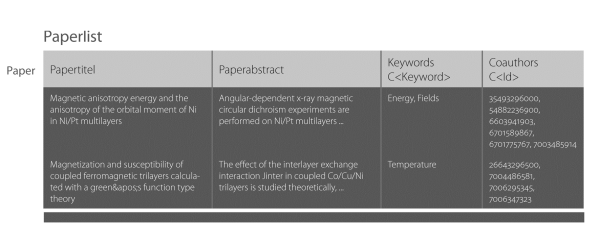
Ilustración 32. Las palabras clave se extraen de los resúmenes de las publicaciones.
Los años o instituciones que faltan se estiman a poder ser aproximadamente. Las fechas que faltan se eligen de antes y después del periodo fijado en cada entrada, y por orden cronológico. Las instituciones se extraen de las publicaciones o se asume que no se ha cambiado de institución. Todas las entradas que faltan se completan con la información curricular del año anterior. Pero incluso con estas correcciones, no puede evitarse la existencia de campos vacíos en la trayectoria si no existen datos en los que basarse.
Conversión de trayectorias a redes
Es posible convertir trayectorias a redes bipartitas en el formato Pajek-.net por medio del conversor TrajectoryToNet, en español Trayectoria a Red, en el workbench de SISOB para un análisis más detallado. Se pueden generar las siguientes redes:
- Red Autor-Institución
- Red Autor-Publicación
- Red Institución-Publicación
- Red Autor-Tema
- Red Tema-Publicación
- Red Tema-Institución
Al combinar estos grafos, se puede obtener instantáneamente, por ejemplo, redes de co-autorías.
Análisis de trayectorias – Flujo 1: La exploración del desarrollo de un único tema en un mapa de Google
El seguimiento que se hace del conocimiento se logra a menudo siguiendo los mecanismos que ayudan a difundirlo. Abramo, D’Angelo y Solazzi (2011), por ejemplo, examinaron aquellos artículos de autoría compartida con idea de hallar la difusión del conocimiento. La incorporación de esta herramienta al workbench de SISOB permite analizar el conocimiento en sí mismo, y deja para un análisis más en detalle el cómo llega hasta allí. Esto puede convertirse en una ventaja, ya que permite detectar la transferencia de conocimiento por rutas menos medibles. En este escenario, los actores son las instituciones de I+D que dan prestigio al conocimiento producido dentro de sus muros. El conocimiento viene representado por temas, descriptores extraídos de los resúmenes de las publicaciones. Aquellas instituciones que publican sobre estos temas se mapean en un mapa de Google de forma similar al enfoque adoptado por Bornmann, Leydesdorff, Walch-Solimenta y Ettl (2011), que mostraban que artículos altamente citados se sitúan en torno a las grandes ciudades. GoogleMapAgent muestra la aparición, distribución geográfica y movimiento de un tema seleccionado a lo largo del tiempo. Los años son las divisiones de tiempo consideradas. Además, es posible analizar el ciclo de vida de un tema: dónde surge, la rapidez y lugares por los que se extiende, si tiende a seguir con una institución o se mueve entre ella y con qué rapidez y dónde comienza su descenso.
Uno de los objetivos de esta herramienta es examinar dónde aparecen los temas por primera vez teniendo en cuenta que no tiene por qué tener un único origen. Incluso podría difundirse en la primera división de tiempo, o distintas instituciones podrían producir el mismo conocimiento de manera simultánea. En un mundo globalizado como el que nos encontramos, con bases de datos públicas, el Google scholar y los medios de comunicación social, los artículos, por ejemplo, están a nuestra disposición en cuestión de segundos. Pero el conocimiento es tácito por naturaleza y está estrechamente vinculado a un actor. Sería interesante ver si, bajo estas circunstancias, la afirmación de Glaeser, Kallal, Scheinkman y Schleifer (1992) de que “los avances intelectuales atraviesan pasillos y calles más fácilmente que océanos y continentes” sigue estando vigente. Finalmente este agente se puede utilizar para la detección de ciclos de vida típicos de los temas, lo que podría llevarnos al desarrollo de patrones de dichos ciclos.
Ejemplificación en el Workbench de SISOB
La colección de datos geográficos que el TrajectoryBuilderSimulator, en español Simulador de Construcción de Trayectorias proporciona para este flujo de trabajo es puramente simulada, sólo se compila con el propósito de explorar las posibilidades que ofrece el GoogleMapAgent. Por lo tanto este análisis no conduce a la obtención de resultados válidos.
La recogida consta de dieciocho entradas desde el 2009 hasta el 2012. Incluye nueve instituciones localizadas en cuatro continentes, tres de las cuales se encuentran en Boston, y dos al sur de Gran Bretaña, para cubrir así distancias de cientos a miles de kilómetros. Las instituciones son la Universidad de Duisburg-Essen, la Universidad de Harvard, El Instituto Tecnológico de Massachusetts, la Universidad de Sidney, la Universidad de Oxford, la Universidad de Cambridge, la Universidad de Zagreb, La Universidad de Boston y la Universidad de Moscú. La herramienta pone a disposición las coordenadas de estas instituciones. Hay ocho temas de donde elegir (Nano tecnología, Ingeniería Biomolecular, Bioinformática, Ciencia de Materiales, Neurociencias, Gráficos de Ordenador, Negocio Electrónico, y Análisis de Redes Sociales). La Nanotecnología aparece en cada entrada y por tanto devolverá la trayectoria completa proporcionando una demostración más clara.
Flujo de trabajo
La ilustración 33 muestra el flujo de trabajo en el workbench de SISOB. El GoogleMapAgent toma la trayectoria que proporciona como input el TrajectoryBuilderSimulator, en español Simulador de Construcción de Trayectorias. El TrajectoryFilterTime, en español el Filtro Temporal de Trayectoria, que puede aplicarse opcionalmente, reduce la trayectoria a entradas entre los años 2009 a 2012. Puesto que el GoogleMapAgent está diseñado para centrarse en un único tema de investigación, es imprescindible que el flujo de trabajo use el TrajectoryFilterTopic, en español Filtro Temático de Trayectoria para determinar el tema de interés, que para este ejemplo es “nanotecnología”. El GoogleMapAgent finalmente transfiere la información de la trayectoria al Keyhole Markup Language (kml), en español el Lenguaje de Marcado de Claves, una notación basada en XML (Lenguaje de Marcado Extensible) para información geográfica con contexto o metadatos, aceptada como input por el GoogleMap-API. El resultado es un enlace a un mapa Google que muestra una red institución-institución para el tema elegido por cada año dentro del plazo seleccionado.
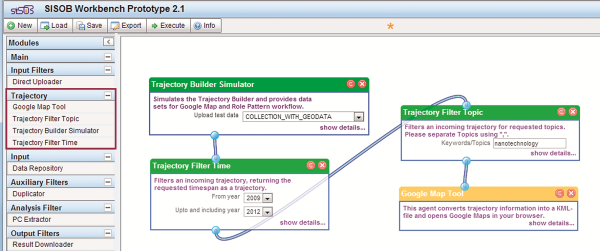
Ilustración 33. Flujo de trabajo en el workbench de SISOB que representa el desarrollo de un tema en GoogleMap.
Tal y como se aprecia en la Ilustración 34, los años se distinguen por el color de sus enlaces. Naturalmente, las redes institucionales para un año forman un grupo altamente cohesionado. Estas redes son combinaciones de redes temática-institución, que incluyen un solo tema tras el filtrado. Al combinar sobre un único tema queda un grupo de instituciones. Los enlaces se mantienen porque uno o más investigadores en la institución origen trabajan en el mismo tema que uno o más investigadores en la institución destino, pero ello no implica que exista cooperación entre dichas instituciones.
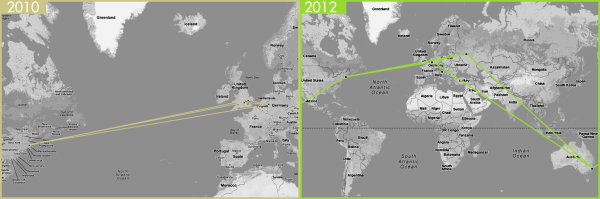
Ilustración 34. La visión de conjunto facilita una estimación aproximada del crecimiento y distribución de la red.
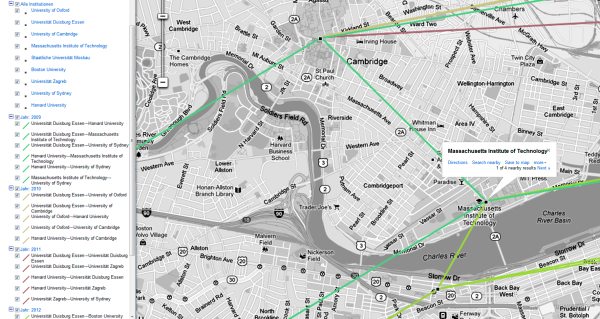
Ilustración 35. Un primer plano muestra las tres universidades de Boston que son parte de la red
Un primer plano del continente americano (ilustración 35) permite un análisis más detallado de las instituciones adheridas en esta área. Tres son las universidades en Boston que forman parte de la red. Un click en el nodo del mapa proporciona el nombre de la institución; un click en el enlace indica origen y destino. Por ejemplo, el Instituto de Tecnología de Massachusetts participó en la investigación del tema durante 2009 y 2012.
Análisis de trayectorias – Flujo 2: El hallazgo de patrones en las trayectorias
A menudo los actores desempeñan un rol en un determinado contexto. En el contexto del intercambio del conocimiento y la movilidad del investigador, estos roles resultan de especial interés si se trata de expandir el conocimiento o indicar cambios. Por lo tanto un rol se traduce en una conducta en el proceso de adquisición, creación y el compartir conocimiento. El RolePatternFilter, en español Filtro de Roles de Patrones, supone una nueva inserción en el workbench de SISOB para poder así identificar a los investigadores que ocupan roles predeterminados. Puesto que la búsqueda está automatizada, pueden acortar significativamente el proceso de búsqueda de actores significativos y servir como punto de partida para la investigación más que como resultado final (Klamma et al. 2006).
Los patrones de newcomer, en español recién llegados o incorporados, terminator, en español desvinculados y continuant, en español estables (ilustración 36) ya se han utilizado como tales puntos de partida (Braun et al. 2001, Wagner y Leydesdorff 2005). Braun et al. (2001) aplicaron estos patrones a la neurociencia y hallaron que tanto los autores incorporados como los desvinculados se unen fundamentalmente a los estables cuando se trata de compartir la autoría de un artículo y que los estables ejercen de mediadores entre los incorporados y los desvinculados.
En el documento D8.2 se mencionaba la importancia de la función del difusor del conocimiento en las redes multicisciplinares. El RolePatternFilter amplía la idea de los roles desde el clásico análisis de redes a las funciones que se derivan de las trayectorias, especialmente desde que las trayectorias se centran en el desarrollo a lo largo del tiempo. Los roles pueden atributos al actor.
Roles Implementados
Para el Workbench de SISOB se implementaron los patrones de incorporados, desvinculados y estables investigados por Braun et al. (2001) (originalmente sugeridos por Desolla Price y Gürsey 1976). Los patrones contemplan la conducta relativa a las publicaciones y se definen en un marco de tres años. Así, un autor recién incorporado no publica durante el primer año, sino durante los dos siguientes; el autor desvinculado publica los dos primeros años, pero no el tercero, mientras que el autor estable publica durante los tres años. Las coincidencias se dan por tanto en el segundo año. Ampliamos a continuación el patrón para cubrir los años entre la primera aparición y la finalización del trabajo, si se encontraban en la franja temporal que se había fijado) Incluso si no hay publicaciones en los años intermedios, el investigador sigue siendo considerado un autor estable. Sin embargo, Si no hubo publicaciones, el investigador se correspondería más con los otros patrones. Decidimos ampliar la franja temporal porque los tests con los datos de CENIDE en el TrajectoryBuilder mostraban que o debido a la pérdida de datos o a los planes de investigación, había investigadores que no habían publicado nada a lo largo de un año. Para llenar ese vacío se puede asumir con seguridad que los investigadores continuaron trabajando en el mismo tema si éste era el mismo el año anterior y posterior al año perdido (Braun et al. 2001) No se puede, sin embargo, aplicar la misma conclusión a los autores incorporados y los desvinculados, puesto que ello significaría el tener que extrapolar hacia adelante o hacia atrás desde la franja de tiempo dada por la trayectoria de partida.
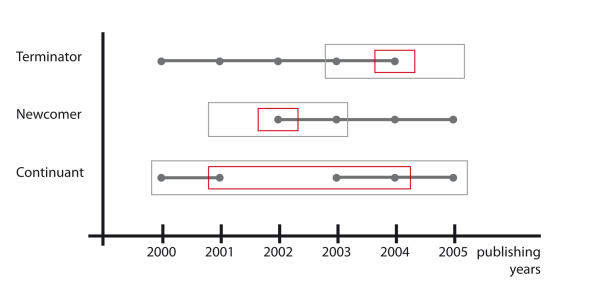
Ilustración 36. Los patrones de incorporados, desvinculados y estables tal como se aplicaron en el Workbench. Las cajas azules indican la franja temporal analizada, las rojas, los años en los que se aplica en patrón
Roles propuestos adicionalmente
Además de los patrones existentes, se han definido los de trendsetter, en español pionero o creador de tendencias, diversifier, en español diversificador y roamer, en español itinerante.
Un trendsetter es un recién llegado a un tema nuevo: él o ella publica sobre el tema durante el primer año de la aparición de éste.
Los diversifiers son investigadores que trabajan en varios temas de manera simultánea: poseen una base muy amplia del saber hacer y podrían actuar como mediadores. El número de temas necesarios para reconocer a un diversifier depende de los datos de entrada. Un investigador se considera un diversifier cuando publica en más temas que la media más la desviación normal calculada a partir de un año aleatorio del conjunto de datos.
Los roamers son científicos que cambian frecuentemente de institución, teniendo, por tanto una gran movilidad geográfica. El patrón se aplica a una ventana de tiempo de tres años: durante ese tiempo el investigador que trabaje en tres instituciones diferentes se considera un roamer.
Ejemplifcación en el workbench de SISOB
El RolePatternFilter trabaja sobre trayectorias porque éstas tienen muchos atributos relacionados con el investigador además de con artículos como ya se ha descrito en el Documento D2.2.
Los datos recogidos y proporcionados por el TrajectoryBuilderSimulator o Simulador de Construcción de Trayectorias y que incluyen a 18 investigadores y 6 años es, de nuevo, una trayectoria puramente imaginaria, diseñada para presentar los patrones de newcomer, terminator y continuant. Por lo tanto, el análisis no conduce a ningún resultado válido. La trayectoria cubre desde el año 2007 al 2012. El tema “genética”, uno de los cinco temas, devuelve la trayectoria completa. La investigadora María Gardener evidencia el patrón de estabilidad prolongada: ha publicado en los años 2007, 2008, 2011 y 2012. Se corresponde con el patrón de autora estable desde 2008 a 2011, pero al mismo tiempo es una newcomer o recién llegada en 2011 y terminator o autora desvinculada en 2008.
Flujo de trabajo
La ilustración 37 representa el flujo para la detección de coincidencias en los patrones en el workbench de SISOB. El TrajectoryBuilderSimulator ofrece la trayectoria; los filtros son opcionales. Por supuesto es posible buscar investigadores nuevos o ya retirados en una trayectoria sin filtrar En el contexto del intercambio de conocimiento resulta de mayor interés filtrar la trayectoria de input por tema. Así por ejemplo, un recién incorporado para el tema “A” es, probablemente, un desvinculado para el tema “B”. Si esto ocurre de forma significativa con un gran volumen de investigadores en un periodo corto de tiempo, indica un cambio de interés en la comunidad científica. El RolePatternFilter trata de identificar las coincidencias para todo el patrón. Las coincidencias se descargan por medio del ResultDownloader, en español Sistema de Descarga de Resultados.
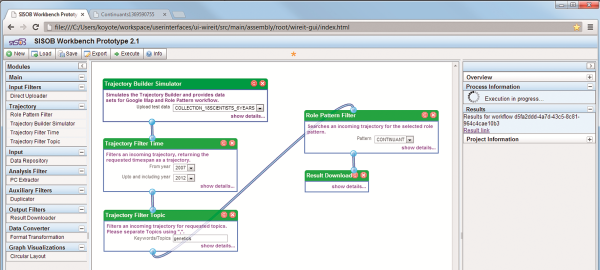
Ilustración 37. Hallazgo de patrones en las trayectorias en el workbench de SISOB
Las coincidencias se enumeran en un archivo txt con iniciales, nombre, años de coincidencia. El archivo contiene además el nombre y la descripción del patrón elegido.
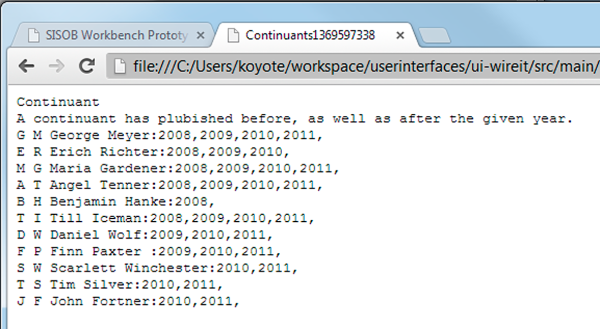
Ilustración 38. Coincidencias para el patrón tomadas de la trayectoria de pruebas
Trabajos futuros
Los patrones Trendsetter, Diversifier y Roamer se aplicarán al RolePatternFilter.La trayectoria de input para el Trendsetter no debe ser filtrada por temas, porque si no el algoritmo de coincidencia no detectará el comienzo de un tema nuevo.
Los roles se pueden considerar como atributos para los investigadores que correspondían con el patrón. Para usar este atributo en el siguiente análisis tendría que integrarse en los datos originales. Esto deja dos posibilidades: Primero, que las coincidencias sirvan como instrucciones de filtrado para la trayectoria original y, segundo, que la trayectoria original se transforme en el formato gráfico de SISOB por medio del TrajectorytoNet converter, en español, el conversor de Trayectoria a Red. A los nodos del investigador se le asignan entonces un rol como propiedad. Ambas posibilidades requieren de la aplicación de otro agente para el Workbench de SISOB.
Referencias
Abramo, G., D’Angelo, C. A., Solazzi, M., 2011. A bibliometric tool to assess the regional dimension of university-industry research collaborations, in: Scientometrics, published online 20. December 2011, DOI: 10.1007/s11192-011-0577-5
Bornmann, L., Leydesdorff, L., Walch-Solimena, C., Ettl, C., 2011 Mapping excellence in the geography of science. An apporach made possible by using Scopus data.
Braun, T., Glanzel, W., Schubert, A., 2001. Publication and Cooperation Patterns of the Authors of Neuroscience Journals. Scientometrics, 51, 499-510.
Desolla Price, D., Gürsey, S., 1976. Studies in scientometrics. Part 1. Transience and continuance in scientific authorship. Internation Forum on Information and Documentation. 1, 17–24.
Glaeser, E., Kallal, H., Scheinkman, J., Shleifer, A., 1992: Growth of the cities. J. Polit Econ, 100, 1126-1152.
Klamma, R., Spaniol, M., Denev, D.,2006. PALADIN: A Pattern Based Approach to Know-ledge Discovery in Digital Social Networks. Proceedings of I-KNOW ’06 Graz, Austria, September 6 – 8
Wagner, C. S., and Leydesdorff, L., 2005. Network Structure, Self-Organization and the Growth of International Collaboration in Science. Research Policy, 34, 1608-1618.
Workshop on “How to measure the impact of scientific results on Society”
On 6 November 2013, Duisburg hosted a workshop within the framework of the SiSOB project to discuss how to study the impact of the results from the scientific studies on society. This is the main goal of the SiSOB project. The attempt during the workshop was to reflect on this main goal and on how the work done along the last three years has helped to meet this challenge.
The workshop started analyzing the case studies addressed by the project (Research mobility, Knowledge Sharing and Peer Review) and used as framework for discussion on issues and open-ended questions with the aim to connect the significant challenge of connecting research results with the citizenship to improve their quality of life. The working day began with the following questions, each one printed in different colored pieces of paper:

- Biggest trends in the past 10 year
- Emerging & future trends
- Chances / opportunities
- Risks (both ways: external threats to topic, risks originating from topic)
- Role of communities and networks (of actors)
- Role of Big Data
- Role of technology and tools

The workshop has been attended by members of the consortium as well as some experts in some of the issues of the project’s thematic framework. They travelled to Duisburg to share the results of the research done and reflect on the open challenges and working lines to be tackled in this type of research. The idea is to make full use of the advances in technology and the new ways to collect data to target the specific objectives derived and match them with research and policy issues, the needs of society and a better life for citizens.
The workshop has become a shared activity where world-coffee discussion activities, proposal of ideas and reflection have been put together.
Keeping in mind the case studies and a set of seven previously listed questions, the most significant items were identified to later go on with the impact of research results on society. The questions examined the cases of use of the project: mobility, knowledge sharing and peer review, which will be dealt in depth in later posts in this blog.

The answers were then categorized in three major themes linked to research: scientific data, technology and policies. The material was then used to discuss on the great challenges to be addressed and on the advances achieved by SiSOB at political level as well as how SiSOB has been able to connect with the actions undertaken and the results achieved:
- Thus, it is interesting to notice how, in projects like SiSOB, an open policy allows access to data to undertake studies which connect research management to its results. SiSOB has demonstrated that the open data can be used in this sort of studies, are quite useful and help us work towards the envisaged objectives.
- A number of items like the existence of unique identifiers, repositories, metadata formats, and protocol of data upload which allow creating observatories to help politicians understand how the investment in research is seen by the society. For the SiSOB project, this type of items connects projects with results and the way how citizens use them. To that aim, data from other sources different to publications or patents are also collected. That is, ‘what people say’ is collected from social networks, blogs, newspapers, reviews, etc.
- Bring the results obtained in the SiSOB Project in line with the results of similar projects like ORCID, SNOWBALL,CERIF, ALTMETRICS, among others. The idea is to record results and work towards the same goal.
- The role of technology, methods and algorithms to draw up conclusions and connect different fields from which to measure aspects related to impact and society.
We have seen in the SiSOB Project how a different approach of studies on science based on models of agent networks joined by their research activities is another way to analyze science results. Information is treated differently and particular emphasis is placed on those items which concern to society; the result is then measured and represented. In this sense, the whole process can be seen and represented as a flow from the sector which generates knowledge to the one which uses it. Our approach attempts to represent it and then look for quantitative measures that can show and display it.
To conclude, several aspects can be highlighted from the workshop and the surrounded discussion. Firstly, and with regard to the workshop held under the world-coffee formula and assisted by three working tables, it was an enriching experience for everyone, especially thanks to the experts’ contributions, who visited every working table and held discussions on the topics proposed with every partner, sharing their knowledge and experience. Secondly, it was also noteworthy the sharing of conclusions of each working table as well as the joint exchange and discussion around Politics, Scientific Data and Technology.
The workshop ended with suggestions and new proposals of analysis and research lines from the experts to the SiSOB researchers, which reveals the long path still to be explored.
El Workshop del Proyecto SiSOB se celebró el 6 de noviembre de 2013 en la ciudad de Duisburg, con el objetivo de debatir sobre cómo estudiar el impacto en la sociedad de los resultados de los estudios científicos. Objetivo que conforma el eje principal de la investigación del Proyecto SiSOB. Este encuentro ha sido un punto de reflexión sobre este objetivo y de cómo los trabajos realizados en el proyecto, durante tres años, han ayudado a alcanzar este reto.
La dinámica de trabajo y reflexión en el workshop ha girado en torno a los casos de estudio tratados en el Proyecto SiSOB (movilidad de los investigadores, intercambio de conocimiento y revisión por pares). A través de preguntas y cuestiones abiertas se trazaban conexiones entre los resultados de la investigación y la sociedad, así como con la mejora de la calidad de vida. El punto de partida de la jornada fueron las siguientes cuestiones, a cada una de las cuales se les adjudicó un color diferente en función de sus características:
- Grandes tendencias de los últimos 10 años
- Tendencias emergentes y futuras
- Oportunidades
- Riesgos (tanto externos al tema como riesgos originados por el propio tema
- Papel de las comunidades y redes (de participantes/actores)
- Papel del Big Data
- Papel de la tecnología y herramientas
En este encuentro han participado miembros del consorcio así como un conjunto de invitados, expertos en temas relacionados con la temática del Proyecto. Todos ellos, se desplazaron a Dusiburg con el objetivo de compartir una jornada de trabajo en la que se pusieron en común los resultados de la investigación realizada. Asimismo, se reflexionó sobre los retos y líneas de trabajo que se abren en el futuro para este tipo de investigaciones. Se trata de aprovechar los avances de la tecnología y nuevas formas de obtener y coleccionar datos hacia objetivos concretos que permitan vincular la investigación con aspectos relacionados con la política, las necesidades de la sociedad y la mejora de la vida de los ciudadanos.
El workshop ha sido un encuentro dinámico, una actividad participativa en la que se ha combinado un world-caffe con actividades de debate, propuesta de ideas y reflexión.
Empezando por los casos de estudio y el conjunto de siete preguntas listadas previamente, se identificaron los elementos más relevantes para avanzar hacia la medida del impacto de los resultados científicos en la sociedad. Las preguntas se trataron desde el enfoque de los casos de estudio del Proyecto: mobilidad, knowledge sharing y peer review. Se tratarán en más detalle en futuros post de este blog.
Las respuestas se reclasificaron en tres grandes temas vinculados con la investigación: datos científicos, tecnología y políticas. Con todo este material se debatió sobre los grandes retos que se plantean y qué avances ha supuesto el Proyecto SiSOB:
- a nivel político y el ser capaz de conectarlas con las acciones realizadas y los resultados obtenidos. Así, la política en abierto es interesante en un proyecto como SiSOB para poder tener acceso a los datos para hacer estudios que conecten la gestión de la investigación con los resultados de la misma. En el proyecto SiSOB ha mostrado que todos los datos que están en abierto pueden ser utilizados para estudios de este tipo, son útiles y permiten trabajar hacia los objetivos planteados.
- elementos como la existencia de identificadores únicos, repositorios, formatos de metadatos, protocolos de carga de datos que permitan crear observatorios que ayuden a los políticos a entender como la sociedad recibe las inversiones que se hacen en investigación. En el proyecto SiSOB este tipo de elementos ayudan a conectar proyectos con resultados y la forma en que la ciudadanía lo usa. Para ello se recopilan datos de diferentes fuentes, no solo las habituales como publicaciones o patentes sino también en “lo que dice la gente” por canales como las redes sociales, blogs, periódicos, comentarios a artículos, etc.
- poner los resultados de SiSOB en consonancia con resultados de proyectos similares tales como ORCID, SNOWBALL, CERIF, ALTMETRICS, entre otros. Se trata de sumar resultados y trabajar hacia el mismo objetivo.
- el papel de la tecnología, los métodos y los algoritmos para descubrir conclusiones y conectar campos diferentes, a partir de los cuales medir aspectos relacionados con el impacto y la sociedad. En el proyecto SiSOB hemos visto como un enfoque diferente de los estudios sobre ciencia basado en modelos de redes de agentes con relaciones basadas en actividades de investigación es otra forma de analizar los resultados de la ciencia. Se modela la información de otra forma y da un énfasis especial a aquellos elementos que destacan relación con la sociedad, se mide y se representa. En este sentido, todo este proceso puede verse y representarse como un flujo desde un sector que genera conocimiento hacia otro que lo usa. Nuestro enfoque fue intentar representarlo y luego buscar medidas cuantitativas para mostrarlo y visualizarlo.
Como conclusión se pueden resaltar varios aspectos, tanto del evento en sí como de las ideas y discusiones que tuvieron lugar en el mismo. En primer lugar, en cuanto a las características del workshop, organizado bajo la fórmula world-coffee y alrededor de tres mesas de trabajo, supuso una experiencia muy enriquecedora para todos los asistentes, especialmente por las aportaciones de los expertos, que visitaron todas las mesas debatiendo con los partner su conocimiento y experiencia acerca de los temas que se discutían. Igualmente valiosa resultó la puesta en común de las conclusiones de cada mesa así como la exposición y debate conjunto alrededor de los temas Politics, Scientific Data y Technology .
El workshop finalizó con una exposición de sugerencias y nuevas propuestas de análisis y líneas de investigación por parte de los expertos a los investigadores de SiSOB, demostrando el amplio camino que aún es necesario explorar en estos ámbitos.
Call: 1st European Conference on Social Networks (EUSN)
The 1st European Conference on Social Networks (EUSN) that will be held at the Faculty of Arts, Autonomous University of Barcelona (UAB) on June 30-July 4, 2014.
This European conference replaces the annual ASNA and UKSNA conference in 2014, having received a regional conference endorsement by INSNA. In this occasion the EUSN will pay special attention to Latin American researchers on social networks in order to foster the creation of a regional conference also in Latin America.
Barcelona, Spain
Knowledge sharing example cases from Germany / Ejemplo de casos de estudio de Alemania sobre el intercambio de información
The nanotechnology case
Nanotechnology is an emerging field within science that is in focus of public interest all over the world. The public interest and the interdisciplinary character are the sampling criteria for choosing nano science as a case for knowledge sharing (see deliverable D8.2). For this purpose we started the analysis of the case study with CENIDE, the Center for Nanointegration at the University Duisburg-Essen.
Network Text Analysis
How would topics differ in pure scientific discourse versus public science communication? To answer this research question, we conducted the following research:
First we collected press releases, press items and publications from the nano technology center CENIDE located at the University Duisburg-Essen. Press releases are announcements produced by a small team mainly responsible for public relations and networking of the nano center. Press items are new articles produced by press and journalists about the nano technology center. Publication abstracts are abstracts of the publications by scientist belonging to the research network.
In the next step we used the text collection as data source for the approach formulated by Leydesdorff & Hellsten (2006) and its adaption for the SISOB project. The approach roughly consists of the following steps:
- Derivation of the occurrence matrix (term occurs in n documents)
- Derivation of the co-occurrence matrix (frequency of terms occurring in the same document)
- Cosine normalization of the co-occurrence matrix
- Factor analysis (showing which terms belong to which frame)
- Visualization:
– Co-occurrence matrix to generate networks
– Factors to determine partitions
The following diagrams show the comparison of the frames (= topic clusters) for the publication abstracts and for the press releases in the year 2008 with the different colors indicating different frames. Figure 1 shows the topics, based on the scientific discourse that means with publication abstracts as data basis. As we can see, besides of global topics (white frame down side) the other main topics for the frame are Spintronics, Spectroscopy, Anisotropy, and Growth of surfaces.

Figure 1. Topic network for CENIDE publication abstracts in 2008
In comparison, Figure 2 shows the CENIDE press items for 2008, representing the topics within the public science communication. Here we can see that this network also contains Spintronics that can also be found in the network extracted from the publication abstracts. Since the network is extracted from press items academic titles are also included in one component. The orange frame in the upper left shows clearly the new master program in nano engineering.

Figure 2. Topic network for CENIDE press releases in 2008
In general we see that the network based on the press releases differs significantly from the network based on the publication abstracts due to the public relation character of press releases.
The press items which are based on the press releases and published by media are more similar to press releases. But they also differ in the sense that more contextual information added by the media can be found in the network.
Concerning the nanotechnology case we can say that using the network of co-occurring words technique enables to detect a change in semantics when the topic moves from the scientific to the press context. In the scientific context, CENIDE is related to specific knowledge and basic research. In the press releases, CENIDE and nanotechnology are strongly related to events, offers and promoting these offers. The press seems to be interested in the persons behind the research and the areas of application. In terms of social impact it is important to tell about these people.
Bibliographic Analysis
How are productivity and cooperation (co-authorship) related? Are the most productive authors also the most collaborative ones? Which role does collaboration play in the field of nanotechnology? To answer these questions, we took a look at the productivity, measured by the degree centrality and the collaboration, measured by the betweeness centrality of the researchers.
The bibliographic data for the nanotechnology analysis has been gathered from SCOPUS database for three different centers with a comparable focus:
- CENIDE (Center for Nano Integration, University of Duisburg-Essen)
- NIM (Nanosystems Initiative Munich)
- KIT (DFG Center for Functional Nanostructures at the Karlsruhe Institute of Technology)
The data set uses the Pajek partition structure to include the different institutions CENIDE, NIM, and KIT.
One result we got based on the comparison of the degree centrality and the productivity of researchers is that productive scientists not necessarily gain a high centrality position in co-authorship networks.
While confronting the researchers with these results some of them were surprised, especially the high productive researchers who usually force single authorship journal publications. They didn’t expect the importance of a collaborative culture of publishing. For nanotechnology it is important to show the difference between degree centrality in co-authorship networks and productivity of individual researchers since there are different publication cultures included in the domain. While for example traditional scientists from the research area of physics usually publish alone or with only few co-authors, mechanical engineers might have a culture of collaborative and interdisciplinary publishing. Especially in cases of young researchers we could observe that one young researcher with a high centrality score also receives a lot of grants.
Another interesting case is the case of one researcher who is not well known for a special paradigm but has developed and optimized methods to produce high amounts of nano particles. In his role as a supplier for nano particles he contributes to different research groups and their research within the center. This leads to his presence as co-author in several papers and he gains a high centrality as a consequence in the resulting co-authorship network.
This shows and underlines the findings from interviews with members of CENIDE and the Network Text Analysis saying that especially enabler roles and providers of enabling technologies are important for the success and impact of scientific communities. Especially universities who usually are interested in hiring famous researchers should consider that enabling is one important factor in the competition to get the best scientists.
The biotechnology case
The case of biotechnology is based on an excellence cluster in Hannover, Germany called Rebirth. It was founded in 2006 as a research cluster addressing difficult health problems especially related to the heart. It seeks the synergy between Medicine, Biochemistry, Physics, Chemistry and Engineering to overcome limitations in traditional Medicine.
The research design is similar to the nanotechnology case based on Network Text Analysis. Here we also conducted both approaches by Diesner/Carley and Leydesdorff/Hellsten to compare topics in press releases and topics in publication abstracts for the years 2008 to 2011.
In general both approaches lead to very similar results. Related to the social dimension they very clearly demonstrate that the different discourses may show and also hide different things. In both approaches we can observe that the scientific discourse represented by the publication abstracts contains the term mice which refers to animal testing. Figure 6 shows this based on the Leydesdorff/Hellsten approach. In contrast the press releases are mainly dominated by terms referring to children and reconstructive therapy approaches especially related to heart issues. In case of children and their growth process it is evident that therapy based on stem cells is one important path to heal heart diseases. On the other hand it seems that public communication in this case is avoiding unpopular topics like animal testing. Healing children with heart diseases seems to benefitthe image of an excellence cluster.

Figure 6. Central term mice referring to animal testing

Figure 7. Topic clusters (frames) in the Rebirth press releases
In sum we can state that for both cases (nanotechnology and biotechnology) the Network Text Analysis approaches are a very practicable way to show differences between public discourses and scientific discourses. Press releases and the more difficult to collect press items are a good way to capture the public discourse. In contrast publication abstracts are practicable since they are available usually without a subscription to specific databases or journals. The difficulty is to understand and interpret the scientific terms and the identified frames. In case of nanotechnology the possibility to interview researchers provided a good way to understand the specifics by asking the scientists. In contrast, the case of biotechnology – without the possibility to interview experts – required intensive internet research to understand the unknown terms and to interpret the found frames.
References
Diesner, J., & Carley, K. M., 2005. Revealing Social Structure from Texts: Meta-Matrix Text Analysis as a novel method for Network Text Analysis. In V. K. Narayanan & D. J. Armstrong, Causal Mapping for Information Systems and Technology Research, 81-108. Harrisburg, PA: Idea Group Publishing.
Leydesdorff, L.; Hellsten, I., 2006: Measuring the Meaning of Words in Contexts: An automated analysis of controversies about ‘Monarch butterflies,’ ‘Frankenfoods,’ and stem cells’. In: Scientometrics, 67, 231-258
Sam Zeini and Nora Pfuetzenreuter Universität Duisburg-Essen (UDE)
El caso de la nanotecnología
La nanotecnología es un nuevo campo dentro del ámbito científico y centro de interés en todo el mundo. Tanto el interés que genera, como su carácter interdisciplinar son criterios que convierten a la nanociencia en un caso de estudio para el intercambio de información (véase el documento D8.2). A tal fin, comenzamos el análisis del caso con CENIDE, el Centro de Nanointegración de la Universidad de Duisburg-Essen.
Análisis de Texto mediante Redes
¿Cómo diferirían los temas en el discurso puramente científico frente al de la comunicación científica destinada al público? Para responder a esta pregunta, realizamos la siguiente investigación:
En primer lugar, recopilamos comunicados de prensa, artículos y publicaciones del centro tecnológico de nanotecnología CENIDE situado en la Universidad de Duisburg-Essen. Los comunicados de prensa son anuncios hechos por un pequeño equipo responsable principalmente de las relaciones públicas y redes sociales del centro nanotecnológico. Los artículos de prensa son artículos nuevos escritos por la prensa y los periodistas sobre el centro nanotecnológico. Los resúmenes de una publicación son los realizados por científicos pertenecientes a una red de investigación.
El siguiente paso fue usar los textos recopilados como fuente de datos para el enfoque formulado por Leydesdorff y Hellsten (2006) y la adaptación de los mismos para el proyecto SISOB. En términos generales, dicho enfoque presenta las siguientes etapas:
- Derivación de la matriz de ocurrencia (el término aparece en n documentos)
- Derivación de la matriz de concurrencia (frecuencia de términos en el mismo documento)
- Normalización del coseno de la matriz de concurrencia
- Análisis del factor (muestra qué términos pertenecen a qué agrupación)
- Visualización:
– Matriz de concurrencia para generar redes
– Factores para determinar cada división
Los siguientes diagramas muestran la comparación de las agrupaciones de temas (=topic clusters) para los resúmenes de publicaciones y los comunicados de prensa del año 2008, en el que cada color representa las diferentes agrupaciones. La Ilustración 1 muestra aquellos basados en el discurso científico que corresponden a los resúmenes de las publicaciones tomados como base de datos. Como se puede observar, además de las agrupaciones de temas globales (agrupación blanca en el lado inferior) también se encuentran las otras agrupaciones principales: Espintrónica, Esprectocopia, Anisotropia y Crecimiento de superficies.
Ilustración 1. Red de agrupaciones de temas para la los resúmenes de la publicación CENIDE en 2008
La ilustración 2 muestra, en comparación, los artículos de prensa de CENIDE para el año 2008, que representan las agrupaciones dentro de la comunicación de la ciencia destinada al público. Como se puede observar, en esta red se encuentra también la Espintrónica, que además puede hallarse en la red extraída de los resúmenes de publicaciones. Puesto que la red se extrae de los artículos de prensa, se incluyen además en un componente las denominaciones académicas. La agrupación naranja en la parte superior izquierda muestra con claridad el nuevo programa máster en nano ingeniería.
Ilustración 2. Red de agrupaciones de temas para los comunicados de prensa de CENIDE en 2008
Podemos ver, en términos generales, que la red basada en los comunicados de prensa difiere significativamente de aquella basada en los resúmenes de las publicaciones, principalmente debido al carácter público de los primeros.
Los artículos de prensa basados en comunicados y publicados por los medios se asemejan más a los comunicados, pero se diferencian también de éstos en que los medios proporcionan más información contextual en la red.
En lo referente al caso de la nanotecnología, podemos decir que el hecho de usar la técnica de red de palabras concurrentes permite detectar un cambio en la semántica cuando el tema se desplaza del contexto científico al de la prensa. En el contexto científico, CENIDE está vinculado al conocimiento específico y la investigación básica. En los artículos de prensa, CENIDE y la nanotecnología comunican actividades, ofertas y promoción de dichas ofertas. La prensa se interesa por cada una de las personas responsables de la investigación y sus áreas de utilidad. En términos de impacto social es importante hablar de estas personas.
Análisis Bibliográfico
¿Cómo se relacionan la productividad y la cooperación (coautoría)? ¿Son los autores más productivos también los más buscan la colaboración? ¿Qué papel desempeña la colaboración en el campo de la nanotecnología? Para responder a estas preguntas, examinamos la productividad científica, medida por el grado de centralidad y la colaboración, que definimos como la centralidad de intermediación entre los investigadores.
Los datos bibliográficos para el análisis de la nanotecnología se han obtenido de la base de datos SCOPUS para tres centros diferentes que cuentan con un enfoque similar:
- CENIDE (Centro de Nanointegración, Universidad de Druisburg-Essen)
- NIM (Nanosystems Initiative Munich)
- KIT (DFG Centro de Nano estructuras Funcionales en el Instituto de Tecnología Karslruhe)
El conjunto de datos utiliza la estructura de división de Pajek para así incluir a las distintas instituciones CENIDE, NIM y KIT.
Uno de los resultados obtenidos basándonos en la comparación del grado de centralidad y la productividad de los investigadores es que los científicos productivos no obtienen necesariamente una alta posición central en las redes de autoría compartida.
Al exponer a los investigadores con estos resultados, muchos de ellos se sorprendieron, especialmente aquellos con una mayor productividad que normalmente potencian la autoría individual de las publicaciones, puesto que no se esperaban la importancia de la publicación compartida. En el caso de la nanotecnología es importante mostrar la diferencia entre el grado de centralidad en redes de autoría compartida y la productividad individual de los investigadores puesto que existe una cultura diferente en cada caso. Mientras que los científicos tradicionales del campo de la investigación publican por lo general de manera individual o contando con algún que otro autor, los ingenieros mecánicos desarrollan una cultura de publicación interdisciplinar y en colaboración. En el caso concreto de investigadores jóvenes se puede observar especialmente el hecho de que reciben además más subvenciones si cuentan con mayor grado de centralidad.
Resulta interesante también el caso del investigador no muy conocido por un aspecto concreto, pero que ha desarrollado y optimizado métodos que producen ingentes cantidades de nano partículas. Como proveedor de nano partículas, contribuye con los diferentes grupos de investigación y su desarrollo en el centro, lo que produce como resultado su participación como coautor en varios artículos proporcionándole una mayor centralidad como resultado de la red establecida de autorías conjuntas.
Todo esto pone de manifiesto los hallazgos derivados de las entrevistas con miembros del CENIDE y del Análisis de Textos mediante Red, que señalan que las funciones de facilitador y proveedor de tecnologías son importantes tanto para el éxito como el impacto de las comunidades científicas. En concreto las universidades, que normalmente procuran contar entre sus filas con investigadores de prestigio, deben considerar que para conseguir a los mejores científicos, éste es un factor importante a tener en cuenta.
El caso de la biotecnología
El caso de la biotecnología se basa en un clúster de excelencia de Hanover, Alemania, denominado Rebirth1, fundado en el año 2006 como clúster de investigación que aborda los problemas de salud, en particular los relacionados con el corazón. El mismo busca la sinergia entre la Medicina, Bioquímica, Física, Química e Ingeniería con el fin de superar las limitaciones de la Medicina tradicional.
El diseño de la investigación es parecido al caso de la nanotecnología basado en el Análisis de Textos mediante Red. Además realizamos aquí ambos enfoques usando el planteamiento de Diesner/Carley y Leydesdorff/Hellsten para comparar las agrupaciones de temas tratados tanto en comunicados de prensa, como en resúmenes de publicaciones para el período comprendido entre los años 2008 y 2011.
En términos generales, ambas enfoques arrojan resultados parecidos. En cuanto a la dimensión social, ambos muestran claramente que discursos diferentes pueden exponer, pero también ocultar, cosas diferentes. Así, en ambos planteamientos, se puede observar que el discurso científico de los resúmenes de publicaciones usa el término “mice” (ratones) para referirse al ensayo con animales. La Ilustración lo muestra basándose en el enfoque de Leydesdorff/Hellsten. Esto contrasta con los comunicados de prensa, dominados principalmente por términos que hacen referencia a los niños y a enfoques terapéuticos reconstructores relacionados especialmente con temas de corazón. En el caso de los niños y su proceso de crecimiento, es evidente que una terapia basada en el uso de células madre es una vía importante para la cura de enfermedades de corazón. Por otra parte, parece que la comunicación de cara al público evita en este caso el uso de temas espinosos como el del ensayo con animales. Curar a niños con enfermedades cardíacas parece beneficiar la imagen de un clúster de excelencia.
Ilustración 6. El término central mice (ratones) para el ensayo con animales
El análisis general de los comunicados de prensa muestra una clara visión general de los temas principales del clúster de excelencia como se aprecia en la Ilustración 7.
Ilustración 7: Topic clusters (agrupaciones de temas) en los comunicados de prensa de Rebirth
En resumen, podemos decir que para ambos casos (nano tecnología y biotecnología) los enfoques de Análisis de Texto mediante Red constituyen una forma muy práctica de exponer las diferencias entre el discurso público y el científico. Los comunicados de prensa así como los más difíciles de recopilar artículos de prensa representan una buena forma de reflejar el discurso público. En cambio, los resúmenes de publicaciones son posibles, puesto que se hallan a disposición de cualquiera sin el requerimiento de una suscripción a una base de datos o revista concreta. La dificultad estriba en la comprensión e interpretación de los términos científicos y sus áreas asociadas. En el caso de la nanotecnología, el poder entrevistar a los investigadores permitió entender con exactitud al poder preguntar directamente a los científicos. En cambio, y en el caso de la biotecnología- sin la posibilidad de contar con la opinión de los expertos- se hizo necesaria una intensa búsqueda en internet para poder entender los términos desconocidos e interpretar las agrupaciones encontradas.
Referencias
Diesner, J., & Carley, K. M., 2005. Revealing Social Structure from Texts: Meta-Matrix Text Analysis as a novel method for Network Text Analysis. In V. K. Narayanan & D. J. Armstrong, Causal Mapping for Information Systems and Technology Research, 81-108. Harrisburg, PA: Idea Group Publishing.
Leydesdorff, L.; Hellsten, I., 2006: Measuring the Meaning of Words in Contexts: An automated analysis of controversies about ‘Monarch butterflies,’ ‘Frankenfoods,’ and stem cells’. In: Scientometrics, 67, 231-258
Sam Zeini and Nora Pfuetzenreuter Universität Duisburg-Essen (UDE)Knowledge sharing international case in the field of software development (Main Path Analysis)
Main Path Analysis and its areas of application
Main Path Analysis (Hummon & Doreian 1989) is a network analysis technique for the scientometric study of scientific citations over a period of time. Its major application is the identification of key publications in the development of a scientific field considering the inherent temporal structure of development. Temporality is explicitly accounted for through the very definition of a directed acyclic graph (DAG) where nodes are single publications and directed edges represent citations between publications. The direction of an edge corresponds to the flow of knowledge from the cited publication to the citing publication. Therefore, these links incorporate both the dimension of content relations and the temporal order of the contributions.
In the citation network of scientific publications within one field, often one important publication is chosen as a starting point of the development of the field. This publication represents the first source. Sink nodes then represent either unimportant or very new publications that have not been cited yet. In this sense there is an implicit notion of time where sources are the oldest (or not cited) publications and sinks are the newest ones.
The main path can be described as the most used path in a citation network taking all possible paths from the source nodes to the sink nodes.
Case 1: Computer Supported Collaborative Learning (CSCL)
For the knowledge sharing cases in the field of computer science we decided to analyze the communities of Computer Supported Collaborative Learning (CSCL) and the community of Artificial Intelligence in Education (AIED). Figure 27 shows the Main Path of one part of the CSCL community from 1990 to 2012. The data has been retrieved from the Web of Knowledge and covers mainly the publications related to Psychology and Pedagogics.

Figure 27. Main Path of the CSCL community 1990 to 2012
We can clearly identify that the path starts with a survey book chapter by Clark and Brennan published in 1991 about the grounding process in communication in an edited book about socially shared cognition. This idea has been taken by Baker and Lund in a frequently cited paper on reflective interaction in the collaborative learning context. This also shows a meaningful development in the field where dialogues like chats and especially the reflective process of explaining in such contexts have been empirically identified as important for the learning processes. As we can see at the end of the main path in the upper left the paper by Dan Suthers and his colleagues defining a framework for conceptualizing, representing, and analyzing distributed interaction leads the main path into a small star. This end of the path indeed shows a side by side development of dialogical interactions and analytics around these interaction and communication processes within the field of Computer Supported Learning.
Case 2: Artificial Intelligence in Education (AIED)
Since the data on the CSCL is limited to parts of the community the contrasting case of Artificial Intelligence in Education (AIED) covers the citation data in the Arnetminer database that uses the DBLP database and also links the data to the ACM database. In this case the selection of the publications based on the venues, such as the AIED conference in our case, is possible due to the structure of DBLP and the references of these selected publications which are used to generate the citation networks for the Main Path Analysis that are given by the ACM data. The network is based on all papers published in the proceedings of AIED. The AIED conference takes place every second year. Our data starts with a seed in the 2009 AIED conference which took place in Brighton. From that point forth we moved back to references to 2000. The analysis uses a simple workflow as shown in Figure 28.

Figure 28. Main Path Analysis workflow for the AIED analysis
Since our implementation of the SPC allows more than one path our case interestingly shows two main components in the path. Figure 29 shows the bigger main component. This component is corresponding to the trend which we already identified for the CSCL community and refers to the support and analysis of interaction and communication within computer supported learning scenarios. The second smaller component in Figure 30 shows the second major area in the field of AIED that contains papers about intelligent tutoring systems that can be seen as a more traditional research domain within this area.
In general the cases show that Main Path Analysis can definitely show trends at a level that is abstract enough to contrast and compare different communities. Our cases for CSCL and AIED can demonstrate clearly that there is one common trend around the support and analysis of interaction and communication in computer supported learning contexts for both communities even though the papers and their authors are different. Main Path Analysis and especially our implementation which allows more than one path can also show special aspects of individual scientific communities like the example of the existing path for Intelligent Tutoring Systems in the AIED community highlights for our cases. The implicit temporal structure also allows the very clear observation of knowledge sharing trajectories for scientific communities and their citation trails.

Figure 29. Interaction and communication support and analysis component

Figure 30. Intelligent Tutoring systems main path component
Referencias
Hummon, N. P. and Doreian, P. 1989. Connectivity in a Citation Network: The Development of DNA Theory. Social Networks, 11, 39-63.
Sam Zeini and Nora Pfuetzenreuter Universität Duisburg-Essen (UDE)
Análisis de la Ruta Principal y áreas de aplicación
El análisis de Ruta Principal (Hummon & Doreian 1989) es una técnica de análisis de redes para el estudio cienciométrico de citas científicas en un periodo de tiempo determinado. Su principal aplicación es la de identificar publicaciones clave en el desarrollo de un ámbito científico teniendo en cuenta la propia estructura temporal de desarrollo. Dicha temporalidad se representa explícitamente mediante la misma definición que se aplica a un grafo acíclico dirigido (DAG) en el que sus nodos corresponden a las publicaciones únicas y las aristas representan las citas entre publicaciones. La dirección de una arista corresponde al flujo de conocimiento desde la publicación citada a la invocación de la misma. Por tanto, estos vínculos aúnan tanto la relación de contenidos como el orden temporal de sus contribuciones.
Con frecuencia se elige una publicación importante de la red de citaciones de publicaciones científicas de un campo concreto como punto de partida para el desarrollo de dicho campo. Esta publicación se convierte así en la primera fuente. Los nodos sumidero representan, pues, a aquellas publicaciones poco significativas o nuevas que aún no han sido citadas. En este sentido existe una noción implícita de tiempo en el que las fuentes representan a las publicaciones más antiguas (o no citadas) y los nodos sumidero se corresponden con las más recientes o nuevas.
La ruta principal puede describirse como la más usada en la red de citas tomando todas las rutas posibles desde los nodos fuente hasta los nodos sumidero.
Caso 1: Aprendizaje en Colaboración Asistido por Ordenador (CSCL)
Para los casos de intercambio de información en el campo informático decidimos analizar las comunidades de Aprendizaje en Colaboración Asistido por Ordenador (CSCL) y la comunidad de Inteligencia Artificial en Educación (AIED). La Ilustración 27 muestra la ruta principal de una parte de la comunidad CSCL desde 1990 hasta 2012. Los datos se han extraído de la Web del Conocimiento y abarcan principalmente las publicaciones relativas a Psicología y Pedagogía.

Ilustración 27. Ruta Principal de la comunidad CSCL de 1990 a 2012.
Se puede identificar claramente que la ruta comienza con el sondeo de un capítulo del libro publicado por Clark y Brennan en 1991 acerca del proceso de la comunicación, en un libro editado sobre el conocimiento socialmente compartido. Esta idea se basa en un artículo de Baker y Lund citado en reiteradas ocasiones acerca de la interacción reflexiva en el contexto del aprendizaje colaborativo, mostrándose, además, un desarrollo significativo en un campo donde diálogos como los chats y, en concreto, el proceso reflexivo de la explicación en dichos contextos han sido empíricamente identificados como importantes en los procesos de aprendizaje. Como se puede ver al final de la ruta principal en la parte superior izquierda, el artículo de Dan Suthers y sus colegas que define un marco para conceptualizar, representar y analizar la interacción distribuida, conduce la ruta principal hacia la estrella pequeña. Este final de ruta, de hecho, muestra un desarrollo en paralelo de las interacciones de diálogo y análisis en torno a estos procesos de interacción y comunicación en el campo del Aprendizaje Asistido por Ordenador.
Caso 2: Inteligencia Artificial en la Educación (AIED)
Puesto que los datos sobre el CSCL se limitan a parte de la comunidad, el caso contrastado de la Inteligencia Artificial en la Educación (AIED) puede cubrir los datos de citación de la base de datos Arnetminer1, que utiliza la base de datos DBLP2 además de vincular los datos a la base ACM3. En este caso, la selección de las publicaciones basada en los eventos, como por ejemplo y en nuestro caso la conferencia AIED, es posible dada la estructura del DBLP y las referencias a las publicaciones seleccionadas usadas para generar las redes de citación para el Análisis de Ruta Principal proporcionadas por la base de datos ACM. La red se basa en todos los artículos publicados en las acciones del AIED. Dicha conferencia tiene lugar cada dos años. Nuestros datos parten de los resultados de la conferencia AIED del año 2009, acontecida en Brighton. De ahí en adelante retrocedemos en busca de referencias al año 2000. El análisis utiliza un sencillo flujo de trabajo como se muestra en la Ilustración 28.
Ilustración 28. Flujo de trabajo del análisis de la ruta principal para el análisis del AIED
Puesto que nuestra aplicación del SPC permite más de una ruta, nuestro caso muestra curiosamente dos componentes principales en la ruta. La Ilustración 29 muestra el mayor de dichos componentes, que se corresponde con la tendencia ya identificada para la comunidad del CSCL y referida al soporte y análisis de la interacción y comunicación en escenarios de aprendizaje asistido por ordenador. El segundo y más pequeño componente de la Ilustración 30 muestra el segundo mayor tema en el campo del AIED y que incluye artículos sobre sistemas tutoriales inteligentes que pueden considerarse más del ámbito tradicional de la investigación.
En general, los casos muestran que el Análisis de Ruta Principal puede ciertamente mostrar las tendencias a un nivel lo suficientemente abstracto como para poder contrastar y comparar diferentes comunidades. Nuestros casos para CSCL y AIED demuestran claramente la existencia de una tendencia común en torno al soporte y análisis de interacción y comunicación en contextos de aprendizaje asistido por ordenador para ambas comunidades, a pesar de que tanto los artículos como los autores de los mismos son diferentes. El Análisis de Ruta Principal y en concreto nuestra aplicación que permite más de una ruta, puede mostrar además aspectos especiales de las comunidades científicas individuales como el ejemplo de la ruta existente para los Sistemas Tutoriales Inteligentes en la comunidad AIED destacada en nuestros casos. La estructura temporal implícita también permite una observación muy clara de las trayectorias de intercambio de información para las comunidades científicas y su consecuente estela de citas.
Ilustración 29. Componentes de soporte y análisis de la interacción y comunicación
Ilustración 30. Componente de la ruta principal en Sistemas Tutoriales Inteligentes
Referencias
Hummon, N. P. and Doreian, P. 1989. Connectivity in a Citation Network: The Development of DNA Theory. Social Networks, 11, 39-63.
Sam Zeini and Nora Pfuetzenreuter Universität Duisburg-Essen (UDE)![]()
Within the frame of the IX Iberoamerican Congress of Science and Technology Indicators, held between October 9 and 11 in Bogota (Colombia), Prof. Dr. Ulrich Hope, from the Universität Duisburg-Essen, presented the Project “SISOB: An Observatory for Science in Society based on Social Models”.

As part of the development of the SISOB Project, a platform for the measurement of the impact of the scientific activity in the society has been created; the platform was presented in the session called Indicators and New Technologies, coordinated by Lautaro Matas (RICYT/OCTS OEI), under the title of “The SISOB Workbench: Supporting analysis workflows on scientometric data”.
The SISOB workbench represents, executes and shares graphical patterns for the analysis of scientometric data. It has a web interface, uses the “pipes & filters” model to represent analysis workflows, allows for an easy inclusion of scripts written in the “R” language and comes with a collection of algorithms for network analysis, among which are several centrality measures and algorithms for sub-community detection. The presentation of the platform also included a demonstration with several example applications.
Other projects presented in the same session were Intelligo: Explorer of the Iberoamerican space, patents and institutional repositories (L. Matas), Atlas of science in Antioquia 1990-2010: Proposal for the measurement of the regional capacities of science (G. Vélez Cuartas, C.A. Aristizábal Botero), NUDO: Open system for the representation and visualisation of data from research groups (E. Llanos, A. Silva), Analysis of the dynamic of production of scientific documents in the emerging departments of the country (2001-2010) (C.F. Ruiz Ramos, E.M. Bueno, J.M. Velandia Sánchez, J.O. Montes de la Barrera, D. Henao Gómez y O.S. Navarro Morato) and Methodology for the interactive mapping of science and technology indicators through a vectorial model of data (A. de Fuentes Martínez).

The Congress was jointly organised by the Network on Science and Technology Indicators –Iberoamerican and Interamerican- (RICYT), the Colombian Observatory on Science and Technology (OCyT) and the Iberoamerican Observatory on Science, Technology and Society (CAEU/OEI). The meeting, which since 2007 is held every three years, has as goals the update of the agenda for discussing science, technology and innovation indicators, the exchange of national and regional experiences related to the elaboration of the indicators, their analysis and use, the identification of the challenges posed by the use of the indicators as tools for the analysis and formulation of the region’s science and technology policies and the analysis of the social representations of science and technology in the Iberoamerican countries, among others.
In short, the Congress is a space for debate, analysis and the strengthening of the achievements reached in the regional measurement of science, technology and innovation. Experts on the measurement of indicators from different countries from the Iberoamerican region and from international organisation, as well as officers from different national organisations on science and technology from the region, take part in these meetings.
To be transfer to the Congress website click on the following link: http://congreso.ricyt.org/.
Lautaro Matas, Natalia Bas Red de Indicadores de Ciencia y Tecnología (RICYT)
En el marco del IX Congreso Iberoamericano de Indicadores de Ciencia y Tecnología, realizado entre el 9 y 11 de octubre en Bogotá (Colombia), el Profesor Ulrich Hope, de la Universität Duisburg-Essen, presentó el Proyecto “SISOB: Un Observatorio para la Ciencia en la Sociedad basado en Modelos Sociales”.
Como parte del desarrollo del Proyecto SISOB, fue creada una plataforma para medir el impacto de la actividad científica en la sociedad; la misma fue presentada bajo el título “La plataforma SISOB: Facilitando flujos de análisis con datos cientométricos” en la mesa de trabajo Indicadores y Nuevas Tecnologías coordinada por Lautaro Matas (RICYT/OCTS OEI).
La plataforma SISOB representa, ejecuta y comparte en forma gráfica patrones de análisis de datos cientométricos. Se puede acceder a ella por una interfaz en web, usa el modelo de “pipes & filters” para representar flujos de análisis, permite la fácil inclusión de programas en el lenguaje “R” y viene con una colección de algoritmos para el análisis de redes, entre los cuales se pueden mencionar varias medidas de centralidad y la detección de sub-comunidades. La presentación de la plataforma SISOB incluyó una demostración con varios ejemplos de aplicación.
Otros de los proyectos presentados en la misma mesa fueron Intelligo: Explorador del espacio iberoamericano, patentes y repositorios institucionales (L. Matas), Atlas de la ciencia de Antioquia 1990-2010: Propuesta para la medición de las capacidades regionales de la ciencia (G. Vélez Cuartas, C.A. Aristizábal Botero), NUDO: Sistema abierto para la representación y visualización de datos de grupos de investigación (E. Llanos, A. Silva), Análisis de la dinámica de producción de documentos científicos en los departamentos emergentes del país (2001-2010) (C.F. Ruiz Ramos, E.M. Bueno, J.M. Velandia Sánchez, J.O. Montes de la Barrera, D. Henao Gómez y O.S. Navarro Morato) y Metodología para el mapeo interactivo de indicadores de ciencia y Tecnología a través de un modelo vectorial de datos (A. de Fuentes Martínez).
El congreso fue organizado en forma conjunta por la Red de Indicadores en Ciencia y Tecnología –Iberoamericana e Interamericana- (RICYT), el Observatorio Colombiano de Ciencia y Tecnología (OCyT) y el Observatorio Iberoamericano de Ciencia, Tecnología y Sociedad (OCTS-OEI). El encuentro, que desde 2007 se realiza cada tres años, tiene como objetivos la actualización de la agenda de discusión sobre indicadores de ciencia, tecnología e innovación, el intercambio de experiencias nacionales y regionales entre los diversos actores vinculados con la producción, análisis y uso de dichos indicadores, la identificación de desafíos que plantea su uso como herramienta para el análisis y formulación de políticas científicas y tecnológicas en la región y el análisis de las diferentes representaciones sociales acerca de la ciencia y la tecnología que se producen en los países iberoamericanos, entre otros.
En suma, el congreso se propone como un espacio de discusión, análisis y profundización de los logros alcanzados en la medición regional de la ciencia, la tecnología y la innovación. Participan del mismo expertos en medición de indicadores de diversos países de Iberoamérica y de organismos internacionales, así como también funcionarios de distintos organismos nacionales de ciencia y tecnología de la región.
Para acceder al portal del congreso ingresé en el siguiente enlace: http://congreso.ricyt.org/.
Lautaro Matas, Natalia Bas Red de Indicadores de Ciencia y Tecnología (RICYT)
Open Call for experts. Workshop on “How to measure the impact of scientific results on Society” 6th November (2013), Duisburg, Germany

Open Access Week: Redefining Impact
The Open Access Week held in October 21-27 is a global event to share and experience the potential benefits of Open Data.
This global event, now in its sixth year, will allow the academic and research community to share and learn on open access and so be able to lay the foundations for the future research environment.

The event is targeted at raising awareness between researchers and institutions of the value that Open Access offers as a resource to disseminate their scientific production, which is appreciated in every scientific discipline where the whole society is involved.
Participating in Open Access Week is simple and the active involvement depends on and adapts to each participant’s needs. Just sign up and participate in the different groups and activities designed for each knowledge and geographic area on the website.
Open Access Week is an invaluable chance to connect the global boost toward open sharing and knowing from the global advancement towards the policy changes at local level. Universities, colleges, research institutes, funding agencies, libraries, and think tanks have used Open Access Week as a platform to gain support on open-access policies in their areas, to study the social and economic benefits of open access, to commit new funds in support of open-access publication, and much more.
Del 21 al 27 de Octubre se desarrollará la gran cita del Acceso Abierto. Un encuentro a nivel global en el que compartir y experimentar las formas y posibilidades que ofrece el open data.
Esta será la sexta edición de este evento, en el que la comunidad académica y de investigación se citan para compartir y aprender en el entorno abierto, y así poder configurar las bases para el futuro entorno de investigación.
El objetivo principal de esta iniciativa es promover el Acceso Abierto y dar a conocer a investigadores e instituciones el valor de la difusión abierta de la producción científica. Un valor que se da en todas las disciplinas científicas y que implica a la sociedad en su conjunto.
La participación en esta iniciativa es fácil y dinámica, adaptándose a las necesidades de cada participante. Sólo es necesario inscribirse y decidir participar en los distintos grupos y actividades que se plantean para cada área de conocimiento y geográfica en la web.
La semana del Acceso Abierto es una oportunidad única para conectar con el impulso mundial hacia la participación abierta. Conociendo desde los avances globales hasta los cambios de política a nivel local. Universidades, colegios, institutos de investigación, agencias de financiación, bibliotecas y grupos de reflexión han utilizado la Semana del Acceso Abierto como una plataforma para conseguir apoyos y opiniones sobre las políticas de libre acceso en sus áreas, estudiar los beneficios sociales y económicos del acceso abierto, plantear nuevos fondos de apoyo a la publicación de acceso abierto, y mucho más.
